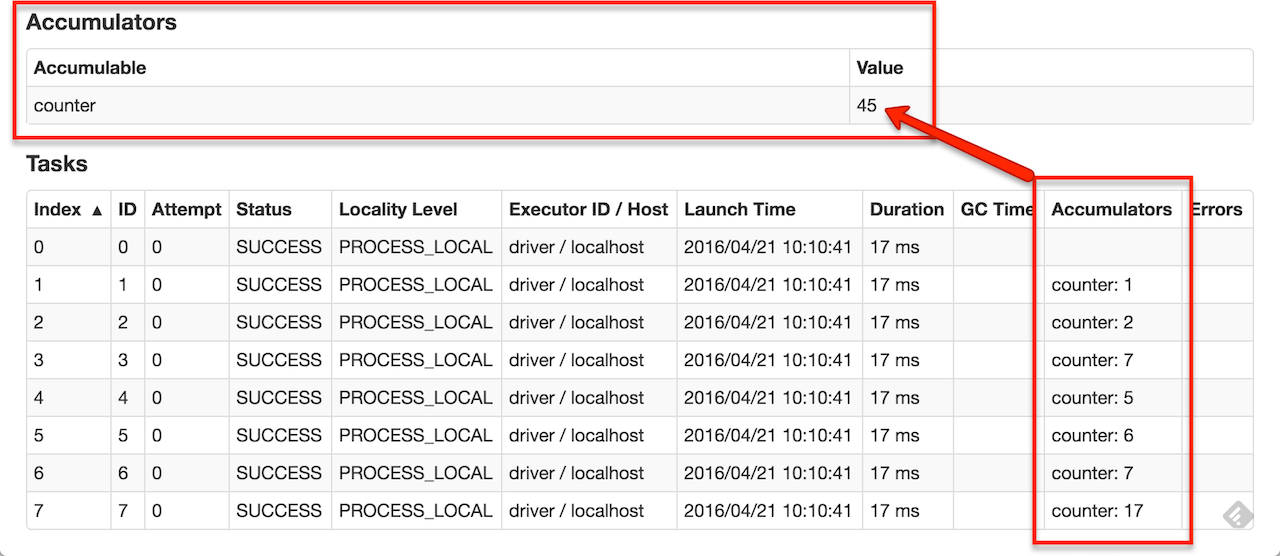
Accumulators
Accumulators are variables that are "added" to through an associative and commutative "add" operation. They act as a container for accumulating partial values across multiple tasks running on executors. They are designed to be used safely and efficiently in parallel and distributed Spark computations and are meant for distributed counters and sums.
You can create built-in accumulators for longs, doubles, or collections or register custom accumulators using the SparkContext.register methods. You can create accumulators with or without a name, but only named accumulators are displayed in web UI (under Stages tab for a given stage).
Figure 1. Accumulators in the Spark UI
Accumulator are write-only variables for executors. They can be added to by executors and read by the driver only.
executor1: accumulator.add(incByExecutor1)
executor2: accumulator.add(incByExecutor2)
driver: println(accumulator.value)Accumulators are not thread-safe. They do not really have to since the DAGScheduler.updateAccumulators method that the driver uses to update the values of accumulators after a task completes (successfully or with a failure) is only executed on a single thread that runs scheduling loop. Beside that, they are write-only data structures for workers that have their own local accumulator reference whereas accessing the value of an accumulator is only allowed by the driver.
Accumulators are serializable so they can safely be referenced in the code executed in executors and then safely send over the wire for execution.
val counter = sc.longAccumulator("counter")
sc.parallelize(1 to 9).foreach(x => counter.add(x))Internally, longAccumulator, doubleAccumulator, and collectionAccumulator methods create the built-in typed accumulators and call SparkContext.register.
|
Tip
|
Read the official documentation about Accumulators. |
AccumulatorV2
abstract class AccumulatorV2[IN, OUT]AccumulatorV2 parameterized class represents an accumulator that accumulates IN values to produce OUT result.
Registering Accumulator (register method)
register(
sc: SparkContext,
name: Option[String] = None,
countFailedValues: Boolean = false): Unitregister is a private[spark] method of the AccumulatorV2 abstract class.
It creates a AccumulatorMetadata metadata object for the accumulator (with a new unique identifier) and registers the accumulator with AccumulatorContext. The accumulator is then registered with ContextCleaner for cleanup.
AccumulatorContext
AccumulatorContext is a private[spark] internal object used to track accumulators by Spark itself using an internal originals lookup table. Spark uses the AccumulatorContext object to register and unregister accumulators.
The originals lookup table maps accumulator identifier to the accumulator itself.
Every accumulator has its own unique accumulator id that is assigned using the internal nextId counter.
AccumulatorContext.SQL_ACCUM_IDENTIFIER
AccumulatorContext.SQL_ACCUM_IDENTIFIER is an internal identifier for Spark SQL’s internal accumulators. The value is sql and Spark uses it to distinguish Spark SQL metrics from others.
Named Accumulators
An accumulator can have an optional name that you can specify when creating an accumulator.
val counter = sc.longAccumulator("counter")AccumulableInfo
AccumulableInfo contains information about a task’s local updates to an Accumulable.
-
idof the accumulator -
optional
nameof the accumulator -
optional partial
updateto the accumulator from a task -
value -
whether or not it is
internal -
whether or not to
countFailedValuesto the final value of the accumulator for failed tasks -
optional
metadata
AccumulableInfo is used to transfer accumulator updates from executors to the driver every executor heartbeat or when a task finishes.
When are Accumulators Updated?
Examples
Example: Distributed Counter
Imagine you are requested to write a distributed counter. What do you think about the following solutions? What are the pros and cons of using it?
val ints = sc.parallelize(0 to 9, 3)
var counter = 0
ints.foreach { n =>
println(s"int: $n")
counter = counter + 1
}
println(s"The number of elements is $counter")How would you go about doing the calculation using accumulators?
Example: Using Accumulators in Transformations and Guarantee Exactly-Once Update
|
Caution
|
FIXME Code with failing transformations (tasks) that update accumulator (Map) with TaskContext info.
|
Example: Custom Accumulator
|
Caution
|
FIXME Improve the earlier example |
Example: Distributed Stopwatch
|
Note
|
This is almost a raw copy of org.apache.spark.ml.util.DistributedStopwatch. |
class DistributedStopwatch(sc: SparkContext, val name: String) {
val elapsedTime: Accumulator[Long] = sc.accumulator(0L, s"DistributedStopwatch($name)")
override def elapsed(): Long = elapsedTime.value
override protected def add(duration: Long): Unit = {
elapsedTime += duration
}
}