Apache Spark
Apache Spark 是一个 具有内存数据处理能力的开源分布式计算框架,可以对大规模数据进行ETL,数据分析, 机器学习和图处理,可以是离线数据(批处理)或者在线的(流处理)拥有丰富简洁的API 支持的语言有: Scala, Python, Java, R, and SQL。
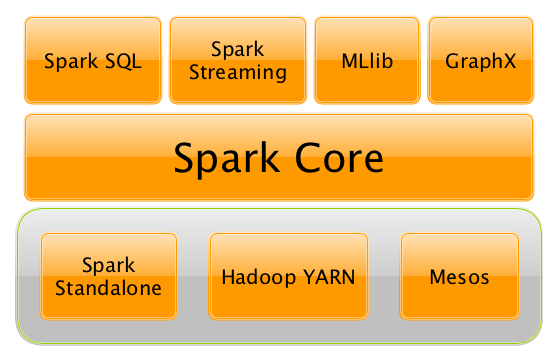
Figure 1. Spark 平台
您还可以将Spark描述为支持 批处理和流式模型 的分布式数据处理引擎,用于SQL查询,图形处理和机器学习。
与Hadoop的基于磁盘的两阶段模型的MapReduce处理引擎相比, Spark的基于内存(in-memory)的多阶段计算引擎允许在内存中进行大多数计算,因此在一些领域往往拥有更好的性能 (有报告称,速度提高了100倍 — Spark officially sets a new record in large-scale sorting!) 例如: 迭代算法或交互式数据挖掘。
Spark旨在提高速度,易用性和交互式分析。
Spark通常称为 计算引擎 或简单的 执行引擎 。
Spark是一个 用于执行复杂的多阶段应用的分布式平台, 比如 机器学习算法,和 交互式即席查询。 Spark为基于内存的计算提供了高效的抽象,称为 弹性分布式数据集RDD。
Spark降低了大规模试用机器学习和预测分析的成本。
Spark主要试用 Scala编写, 但是支持其他语言,比如:Java, Python, 和 R。
如果你有大量的数据需要低延迟处理,传统的MapReduce程序可能无法圣人,这时可以用Spark替代。
-
在任何数据源中访问任何数据类型。
-
巨大的存储和数据处理需求
Apache Spark 包括 SQL (DataFrames), 流出来, 机器学习 (pipelines) 和 graph 图计算引擎,它们都基于Spark Core。你可以使用统一的API来试用它们。
Spark像运行在集群中一样运行在本地。它可以运行在Hadoop YARN, Apache Mesos, 独立的 或者云端(Amazon EC2 或 IBM Bluemix)。
Spark can access data from many data sources.
Apache Spark’s Streaming and SQL programming models with MLlib and GraphX make it easier for developers and data scientists to build applications that exploit machine learning and graph analytics.
At a high level, any Spark application creates RDDs out of some input, run (lazy) transformations of these RDDs to some other form (shape), and finally perform actions to collect or store data. Not much, huh?
You can look at Spark from programmer’s, data engineer’s and administrator’s point of view. And to be honest, all three types of people will spend quite a lot of their time with Spark to finally reach the point where they exploit all the available features. Programmers use language-specific APIs (and work at the level of RDDs using transformations and actions), data engineers use higher-level abstractions like DataFrames or Pipelines APIs or external tools (that connect to Spark), and finally it all can only be possible to run because administrators set up Spark clusters to deploy Spark applications to.
It is Spark’s goal to be a general-purpose computing platform with various specialized applications frameworks on top of a single unified engine.
|
Note
|
When you hear "Apache Spark" it can be two things — the Spark engine aka Spark Core or the Apache Spark open source project which is an "umbrella" term for Spark Core and the accompanying Spark Application Frameworks, i.e. Spark SQL, Spark Streaming, Spark MLlib and Spark GraphX that sit on top of Spark Core and the main data abstraction in Spark called RDD - Resilient Distributed Dataset. |
Why Spark
Let’s list a few of the many reasons for Spark. We are doing it first, and then comes the overview that lends a more technical helping hand.
Easy to Get Started
Spark offers spark-shell that makes for a very easy head start to writing and running Spark applications on the command line on your laptop.
You could then use Spark Standalone built-in cluster manager to deploy your Spark applications to a production-grade cluster to run on a full dataset.
Unified Engine for Diverse Workloads
As said by Matei Zaharia - the author of Apache Spark - in Introduction to AmpLab Spark Internals video (quoting with few changes):
One of the Spark project goals was to deliver a platform that supports a very wide array of diverse workflows - not only MapReduce batch jobs (there were available in Hadoop already at that time), but also iterative computations like graph algorithms or Machine Learning.
And also different scales of workloads from sub-second interactive jobs to jobs that run for many hours.
Spark combines batch, interactive, and streaming workloads under one rich concise API.
Spark supports near real-time streaming workloads via Spark Streaming application framework.
ETL workloads and Analytics workloads are different, however Spark attempts to offer a unified platform for a wide variety of workloads.
Graph and Machine Learning algorithms are iterative by nature and less saves to disk or transfers over network means better performance.
There is also support for interactive workloads using Spark shell.
You should watch the video What is Apache Spark? by Mike Olson, Chief Strategy Officer and Co-Founder at Cloudera, who provides a very exceptional overview of Apache Spark, its rise in popularity in the open source community, and how Spark is primed to replace MapReduce as the general processing engine in Hadoop.
Leverages the Best in distributed batch data processing
When you think about distributed batch data processing, Hadoop naturally comes to mind as a viable solution.
Spark draws many ideas out of Hadoop MapReduce. They work together well - Spark on YARN and HDFS - while improving on the performance and simplicity of the distributed computing engine.
For many, Spark is Hadoop++, i.e. MapReduce done in a better way.
And it should not come as a surprise, without Hadoop MapReduce (its advances and deficiencies), Spark would not have been born at all.
RDD - Distributed Parallel Scala Collections
As a Scala developer, you may find Spark’s RDD API very similar (if not identical) to Scala’s Collections API.
It is also exposed in Java, Python and R (as well as SQL, i.e. SparkSQL, in a sense).
So, when you have a need for distributed Collections API in Scala, Spark with RDD API should be a serious contender.
Rich Standard Library
Not only can you use map and reduce (as in Hadoop MapReduce jobs) in Spark, but also a vast array of other higher-level operators to ease your Spark queries and application development.
It expanded on the available computation styles beyond the only map-and-reduce available in Hadoop MapReduce.
Unified development and deployment environment for all
Regardless of the Spark tools you use - the Spark API for the many programming languages supported - Scala, Java, Python, R, or the Spark shell, or the many Spark Application Frameworks leveraging the concept of RDD, i.e. Spark SQL, Spark Streaming, Spark MLlib and Spark GraphX, you still use the same development and deployment environment to for large data sets to yield a result, be it a prediction (Spark MLlib), a structured data queries (Spark SQL) or just a large distributed batch (Spark Core) or streaming (Spark Streaming) computation.
It’s also very productive of Spark that teams can exploit the different skills the team members have acquired so far. Data analysts, data scientists, Python programmers, or Java, or Scala, or R, can all use the same Spark platform using tailor-made API. It makes for bringing skilled people with their expertise in different programming languages together to a Spark project.
Interactive Exploration / Exploratory Analytics
It is also called ad hoc queries.
Using the Spark shell you can execute computations to process large amount of data (The Big Data). It’s all interactive and very useful to explore the data before final production release.
Also, using the Spark shell you can access any Spark cluster as if it was your local machine. Just point the Spark shell to a 20-node of 10TB RAM memory in total (using --master) and use all the components (and their abstractions) like Spark SQL, Spark MLlib, Spark Streaming, and Spark GraphX.
Depending on your needs and skills, you may see a better fit for SQL vs programming APIs or apply machine learning algorithms (Spark MLlib) from data in graph data structures (Spark GraphX).
Single Environment
Regardless of which programming language you are good at, be it Scala, Java, Python, R or SQL, you can use the same single clustered runtime environment for prototyping, ad hoc queries, and deploying your applications leveraging the many ingestion data points offered by the Spark platform.
You can be as low-level as using RDD API directly or leverage higher-level APIs of Spark SQL (Datasets), Spark MLlib (ML Pipelines), Spark GraphX (Graphs) or Spark Streaming (DStreams).
Or use them all in a single application.
The single programming model and execution engine for different kinds of workloads simplify development and deployment architectures.
Data Integration Toolkit with Rich Set of Supported Data Sources
Spark can read from many types of data sources — relational, NoSQL, file systems, etc. — using many types of data formats - Parquet, Avro, CSV, JSON.
Both, input and output data sources, allow programmers and data engineers use Spark as the platform with the large amount of data that is read from or saved to for processing, interactively (using Spark shell) or in applications.
Tools unavailable then, at your fingertips now
As much and often as it’s recommended to pick the right tool for the job, it’s not always feasible. Time, personal preference, operating system you work on are all factors to decide what is right at a time (and using a hammer can be a reasonable choice).
Spark embraces many concepts in a single unified development and runtime environment.
-
Machine learning that is so tool- and feature-rich in Python, e.g. SciKit library, can now be used by Scala developers (as Pipeline API in Spark MLlib or calling
pipe()). -
DataFrames from R are available in Scala, Java, Python, R APIs.
-
Single node computations in machine learning algorithms are migrated to their distributed versions in Spark MLlib.
This single platform gives plenty of opportunities for Python, Scala, Java, and R programmers as well as data engineers (SparkR) and scientists (using proprietary enterprise data warehouses with Thrift JDBC/ODBC Server in Spark SQL).
Mind the proverb if all you have is a hammer, everything looks like a nail, too.
Low-level Optimizations
Apache Spark uses a directed acyclic graph (DAG) of computation stages (aka execution DAG). It postpones any processing until really required for actions. Spark’s lazy evaluation gives plenty of opportunities to induce low-level optimizations (so users have to know less to do more).
Mind the proverb less is more.
Excels at low-latency iterative workloads
Spark supports diverse workloads, but successfully targets low-latency iterative ones. They are often used in Machine Learning and graph algorithms.
Many Machine Learning algorithms require plenty of iterations before the result models get optimal, like logistic regression. The same applies to graph algorithms to traverse all the nodes and edges when needed. Such computations can increase their performance when the interim partial results are stored in memory or at very fast solid state drives.
Spark can cache intermediate data in memory for faster model building and training. Once the data is loaded to memory (as an initial step), reusing it multiple times incurs no performance slowdowns.
Also, graph algorithms can traverse graphs one connection per iteration with the partial result in memory.
Less disk access and network can make a huge difference when you need to process lots of data, esp. when it is a BIG Data.
ETL done easier
Spark gives Extract, Transform and Load (ETL) a new look with the many programming languages supported - Scala, Java, Python (less likely R). You can use them all or pick the best for a problem.
Scala in Spark, especially, makes for a much less boiler-plate code (comparing to other languages and approaches like MapReduce in Java).
Unified Concise High-Level API
Spark offers a unified, concise, high-level APIs for batch analytics (RDD API), SQL queries (Dataset API), real-time analysis (DStream API), machine learning (ML Pipeline API) and graph processing (Graph API).
Developers no longer have to learn many different processing engines and platforms, and let the time be spent on mastering framework APIs per use case (atop a single computation engine Spark).
Different kinds of data processing using unified API
Spark offers three kinds of data processing using batch, interactive, and stream processing with the unified API and data structures.
Little to no disk use for better performance
In the no-so-long-ago times, when the most prevalent distributed computing framework was Hadoop MapReduce, you could reuse a data between computation (even partial ones!) only after you’ve written it to an external storage like Hadoop Distributed Filesystem (HDFS). It can cost you a lot of time to compute even very basic multi-stage computations. It simply suffers from IO (and perhaps network) overhead.
One of the many motivations to build Spark was to have a framework that is good at data reuse.
Spark cuts it out in a way to keep as much data as possible in memory and keep it there until a job is finished. It doesn’t matter how many stages belong to a job. What does matter is the available memory and how effective you are in using Spark API (so no shuffle occur).
The less network and disk IO, the better performance, and Spark tries hard to find ways to minimize both.
Fault Tolerance included
Faults are not considered a special case in Spark, but obvious consequence of being a parallel and distributed system. Spark handles and recovers from faults by default without particularly complex logic to deal with them.
Small Codebase Invites Contributors
Spark’s design is fairly simple and the code that comes out of it is not huge comparing to the features it offers.
The reasonably small codebase of Spark invites project contributors - programmers who extend the platform and fix bugs in a more steady pace.