scala> val kv = (0 to 5) zip Stream.continually(5)
kv: scala.collection.immutable.IndexedSeq[(Int, Int)] = Vector((0,5), (1,5), (2,5), (3,5), (4,5), (5,5))
scala> val kw = (0 to 5) zip Stream.continually(10)
kw: scala.collection.immutable.IndexedSeq[(Int, Int)] = Vector((0,10), (1,10), (2,10), (3,10), (4,10), (5,10))
scala> val kvR = sc.parallelize(kv)
kvR: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:26
scala> val kwR = sc.parallelize(kw)
kwR: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[4] at parallelize at <console>:26
scala> val joined = kvR join kwR
joined: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[10] at join at <console>:32
scala> joined.toDebugString
res7: String =
(8) MapPartitionsRDD[10] at join at <console>:32 []
| MapPartitionsRDD[9] at join at <console>:32 []
| CoGroupedRDD[8] at join at <console>:32 []
+-(8) ParallelCollectionRDD[3] at parallelize at <console>:26 []
+-(8) ParallelCollectionRDD[4] at parallelize at <console>:26 []RDD shuffling
|
Tip
|
Read the official documentation about the topic Shuffle operations. It is still better than this page. |
Shuffling is a process of redistributing data across partitions (aka repartitioning) that may or may not cause moving data across JVM processes or even over the wire (between executors on separate machines).
Shuffling is the process of data transfer between stages.
|
Tip
|
Avoid shuffling at all cost. Think about ways to leverage existing partitions. Leverage partial aggregation to reduce data transfer. |
By default, shuffling doesn’t change the number of partitions, but their content.
-
Avoid
groupByKeyand usereduceByKeyorcombineByKeyinstead.-
groupByKeyshuffles all the data, which is slow. -
reduceByKeyshuffles only the results of sub-aggregations in each partition of the data.
-
Example - join
PairRDD offers join transformation that (quoting the official documentation):
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key.
Let’s have a look at an example and see how it works under the covers:
It doesn’t look good when there is an "angle" between "nodes" in an operation graph. It appears before the join operation so shuffle is expected.
Here is how the job of executing joined.count looks in Web UI.
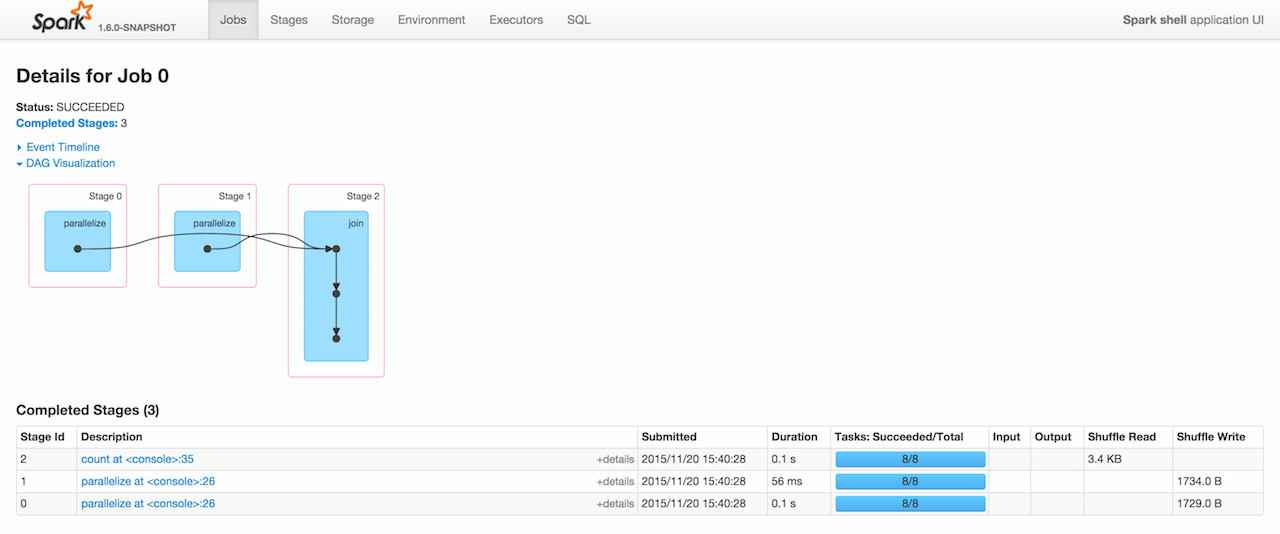
Figure 1. Executing
joined.countThe screenshot of Web UI shows 3 stages with two parallelize to Shuffle Write and count to Shuffle Read. It means shuffling has indeed happened.
|
Caution
|
FIXME Just learnt about sc.range(0, 5) as a shorter version of sc.parallelize(0 to 5) |
join operation is one of the cogroup operations that uses defaultPartitioner, i.e. walks through the RDD lineage graph (sorted by the number of partitions decreasing) and picks the partitioner with positive number of output partitions. Otherwise, it checks spark.default.parallelism setting and if defined picks HashPartitioner with the default parallelism of the SchedulerBackend.
join is almost CoGroupedRDD.mapValues.
|
Caution
|
FIXME the default parallelism of scheduler backend |