Datasets — Strongly-Typed DataFrames with Encoders
Dataset is Spark SQL’s strongly-typed structured query API for working with semi- and structured data, i.e. records with a known schema, by means of encoders.
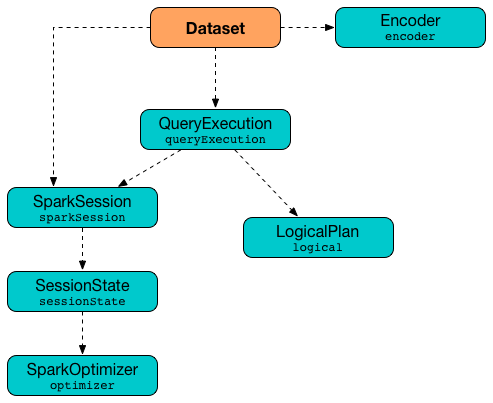
Figure 1. Dataset’s Internals
Datasets are lazy and structured query expressions are only triggered when an action is invoked. Internally, a Dataset represents a logical plan that describes the computation query required to produce the data (for a given Spark SQL session).
A Dataset is a result of executing a query expression against data storage like files, Hive tables or JDBC databases. The structured query expression can be described by a SQL query, a Column-based SQL expression or a Scala/Java lambda function. And that is why Dataset operations are available in three variants.
scala> val dataset = (0 to 4).toDS
dataset: org.apache.spark.sql.Dataset[Int] = [value: int]
// Variant 1: filter operator accepts a Scala function
dataset.filter(n => n % 2 == 0).count
// Variant 2: filter operator accepts a Column-based SQL expression
dataset.filter('value % 2 === 0).count
// Variant 3: filter operator accepts a SQL query
dataset.filter("value % 2 = 0").countThe Dataset API offers declarative and type-safe operators that makes for an improved experience for data processing (comparing to DataFrames that were a set of index- or column name-based Rows).
|
Note
|
As of Spark 2.0.0, DataFrame - the flagship data abstraction of previous versions of Spark SQL - is currently a mere type alias for See package object sql. |
Dataset offers convenience of RDDs with the performance optimizations of DataFrames and the strong static type-safety of Scala. The last feature of bringing the strong type-safety to DataFrame makes Dataset so appealing. All the features together give you a more functional programming interface to work with structured data.
scala> spark.range(1).filter('id === 0).explain(true)
== Parsed Logical Plan ==
'Filter ('id = 0)
+- Range (0, 1, splits=8)
== Analyzed Logical Plan ==
id: bigint
Filter (id#51L = cast(0 as bigint))
+- Range (0, 1, splits=8)
== Optimized Logical Plan ==
Filter (id#51L = 0)
+- Range (0, 1, splits=8)
== Physical Plan ==
*Filter (id#51L = 0)
+- *Range (0, 1, splits=8)
scala> spark.range(1).filter(_ == 0).explain(true)
== Parsed Logical Plan ==
'TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], unresolveddeserializer(newInstance(class java.lang.Long))
+- Range (0, 1, splits=8)
== Analyzed Logical Plan ==
id: bigint
TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], newInstance(class java.lang.Long)
+- Range (0, 1, splits=8)
== Optimized Logical Plan ==
TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], newInstance(class java.lang.Long)
+- Range (0, 1, splits=8)
== Physical Plan ==
*Filter <function1>.apply
+- *Range (0, 1, splits=8)It is only with Datasets to have syntax and analysis checks at compile time (that was not possible using DataFrame, regular SQL queries or even RDDs).
Using Dataset objects turns DataFrames of Row instances into a DataFrames of case classes with proper names and types (following their equivalents in the case classes). Instead of using indices to access respective fields in a DataFrame and cast it to a type, all this is automatically handled by Datasets and checked by the Scala compiler.
Datasets use Catalyst Query Optimizer and Tungsten to optimize query performance.
A Dataset object requires a SparkSession, a QueryExecution plan, and an Encoder (for fast serialization to and deserialization from InternalRow).
If however a LogicalPlan is used to create a Dataset, the logical plan is first executed (using the current SessionState in the SparkSession) that yields the QueryExecution plan.
A Dataset is Queryable and Serializable, i.e. can be saved to a persistent storage.
|
Note
|
SparkSession and QueryExecution are transient attributes of a Dataset and therefore do not participate in Dataset serialization. The only firmly-tied feature of a Dataset is the Encoder.
|
You can convert a type-safe Dataset to a "untyped" DataFrame or access the RDD that is generated after executing the query. It is supposed to give you a more pleasant experience while transitioning from the legacy RDD-based or DataFrame-based APIs you may have used in the earlier versions of Spark SQL or encourage migrating from Spark Core’s RDD API to Spark SQL’s Dataset API.
The default storage level for Datasets is MEMORY_AND_DISK because recomputing the in-memory columnar representation of the underlying table is expensive. You can however persist a Dataset.
Spark 2.0 has introduced a new query model called Structured Streaming for continuous incremental execution of structured queries. That made possible to consider Datasets a static and bounded as well as streaming and unbounded data sets with a single unified API for different execution models.
A Dataset is local if it was created from local collections using SparkSession.emptyDataset or SparkSession.createDataset methods and their derivatives like toDF. If so, the queries on the Dataset can be optimized and run locally, i.e. without using Spark executors.
|
Note
|
Dataset has the QueryExecution analyzed and checked.
|
queryExecution Attribute
queryExecution is a required parameter of a Dataset.
val dataset: Dataset[Int] = ...
dataset.queryExecutionIt is a part of the Developer API of the Dataset class.
Creating Datasets
If LogicalPlan is used to create a Dataset, it is executed (using the current SessionState) to create a corresponding QueryExecution.
Implicit Type Conversions to Datasets — toDS and toDF methods
DatasetHolder case class offers three methods that do the conversions from Seq[T] or RDD[T] types to a Dataset[T]:
-
toDS(): Dataset[T] -
toDF(): DataFrame -
toDF(colNames: String*): DataFrame
|
Note
|
DataFrame is a mere type alias for Dataset[Row] since Spark 2.0.0.
|
DatasetHolder is used by SQLImplicits that is available to use after importing implicits object of SparkSession.
val spark: SparkSession = ...
import spark.implicits._
scala> val ds = Seq("I am a shiny Dataset!").toDS
ds: org.apache.spark.sql.Dataset[String] = [value: string]
scala> val df = Seq("I am an old grumpy DataFrame!").toDF
df: org.apache.spark.sql.DataFrame = [value: string]
scala> val df = Seq("I am an old grumpy DataFrame!").toDF("text")
df: org.apache.spark.sql.DataFrame = [text: string]
scala> val ds = sc.parallelize(Seq("hello")).toDS
ds: org.apache.spark.sql.Dataset[String] = [value: string]|
Note
|
This import of |
val spark: SparkSession = ...
import spark.implicits._
case class Token(name: String, productId: Int, score: Double)
val data = Seq(
Token("aaa", 100, 0.12),
Token("aaa", 200, 0.29),
Token("bbb", 200, 0.53),
Token("bbb", 300, 0.42))
// Transform data to a Dataset[Token]
// It doesn't work with type annotation
// https://issues.apache.org/jira/browse/SPARK-13456
val ds = data.toDS
// ds: org.apache.spark.sql.Dataset[Token] = [name: string, productId: int ... 1 more field]
// Transform data into a DataFrame with no explicit schema
val df = data.toDF
// Transform DataFrame into a Dataset
val ds = df.as[Token]
scala> ds.show
+----+---------+-----+
|name|productId|score|
+----+---------+-----+
| aaa| 100| 0.12|
| aaa| 200| 0.29|
| bbb| 200| 0.53|
| bbb| 300| 0.42|
+----+---------+-----+
scala> ds.printSchema
root
|-- name: string (nullable = true)
|-- productId: integer (nullable = false)
|-- score: double (nullable = false)
// In DataFrames we work with Row instances
scala> df.map(_.getClass.getName).show(false)
+--------------------------------------------------------------+
|value |
+--------------------------------------------------------------+
|org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema|
|org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema|
|org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema|
|org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema|
+--------------------------------------------------------------+
// In Datasets we work with case class instances
scala> ds.map(_.getClass.getName).show(false)
+---------------------------+
|value |
+---------------------------+
|$line40.$read$$iw$$iw$Token|
|$line40.$read$$iw$$iw$Token|
|$line40.$read$$iw$$iw$Token|
|$line40.$read$$iw$$iw$Token|
+---------------------------+Internals of toDS
Internally, the Scala compiler makes toDS implicitly available to any Seq[T] (using SQLImplicits.localSeqToDatasetHolder implicit method).
|
Note
|
This and other implicit methods are in scope whenever you do import spark.implicits._.
|
The input Seq[T] is converted into Dataset[T] by means of SQLContext.createDataset that in turn passes all calls on to SparkSession.createDataset. Once created, the Dataset[T] is wrapped in DatasetHolder[T] with toDS that just returns the input ds.
Queryable
|
Caution
|
FIXME |
Tracking Multi-Job SQL Query Executions — withNewExecutionId Internal Method
withNewExecutionId[U](body: => U): UwithNewExecutionId is a private[sql] operator that executes the input body action using SQLExecution.withNewExecutionId that sets the execution id local property set.
|
Note
|
It is used in foreach, foreachPartition, and (private) collect.
|
Creating DataFrame — ofRows Internal Method
ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame|
Note
|
ofRows is a private[sql] operator that can only be accessed from code in org.apache.spark.sql package. It is not a part of Dataset's public API.
|
ofRows returns DataFrame (which is the type alias for Dataset[Row]). ofRows uses RowEncoder to convert the schema (based on the input logicalPlan logical plan).
Internally, ofRows prepares the input logicalPlan for execution and creates a Dataset[Row] with the current SparkSession, the QueryExecution and RowEncoder.