package pl.japila.spark
import org.apache.spark.{SparkContext, SparkConf}
object SparkMeApp {
def main(args: Array[String]) {
val masterURL = "local[*]" (1)
val conf = new SparkConf() (2)
.setAppName("SparkMe Application")
.setMaster(masterURL)
val sc = new SparkContext(conf) (3)
val fileName = util.Try(args(0)).getOrElse("build.sbt")
val lines = sc.textFile(fileName).cache() (4)
val c = lines.count() (5)
println(s"There are $c lines in $fileName")
}
}Anatomy of Spark Application
Every Spark application starts at instantiating a Spark context. Without a Spark context no computation can ever be started using Spark services.
|
Note
|
A Spark application is an instance of SparkContext. Or, put it differently, a Spark context constitutes a Spark application. |
For it to work, you have to create a Spark configuration using SparkConf or use a custom SparkContext constructor.
-
Master URL to connect the application to
-
Create Spark configuration
-
Create Spark context
-
Create
linesRDD -
Execute
countaction
|
Tip
|
Spark shell creates a Spark context and SQL context for you at startup. |
When a Spark application starts (using spark-submit script or as a standalone application), it connects to Spark master as described by master URL. It is part of Spark context’s initialization.
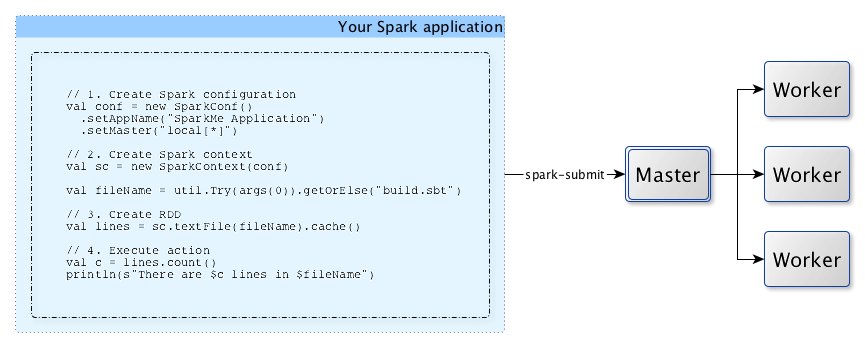
Figure 1. Submitting Spark application to master using master URL
|
Note
|
Your Spark application can run locally or on the cluster which is based on the cluster manager and the deploy mode (--deploy-mode). Refer to Deployment Modes.
|
You can then create RDDs, transform them to other RDDs and ultimately execute actions. You can also cache interim RDDs to speed up data processing.
After all the data processing is completed, the Spark application finishes by stopping the Spark context.