$ jps -lm 71253 org.apache.spark.deploy.yarn.ExecutorLauncher --arg 192.168.99.1:50188 --properties-file /tmp/hadoop-jacek/nm-local-dir/usercache/jacek/appcache/application_1468961163409_0001/container_1468961163409_0001_01_000001/__spark_conf__/__spark_conf__.properties 70631 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 70934 org.apache.spark.deploy.SparkSubmit --master yarn --class org.apache.spark.repl.Main --name Spark shell spark-shell 71320 sun.tools.jps.Jps -lm 70731 org.apache.hadoop.yarn.server.nodemanager.NodeManager
ApplicationMaster (aka ExecutorLauncher)
ApplicationMaster class acts as the YARN ApplicationMaster for a Spark application running on a YARN cluster (which is commonly called Spark on YARN).
It uses YarnAllocator to manage YARN containers for executors.
ApplicationMaster is a standalone application that YARN NodeManager runs inside a YARN resource container and is responsible for the execution of a Spark application on YARN.
When created ApplicationMaster class is given a YarnRMClient (which is responsible for registering and unregistering a Spark application).
|
Note
|
ExecutorLauncher is a custom |
ApplicationMaster (and ExecutorLauncher) is launched as a result of Client creating a ContainerLaunchContext to launch Spark on YARN.
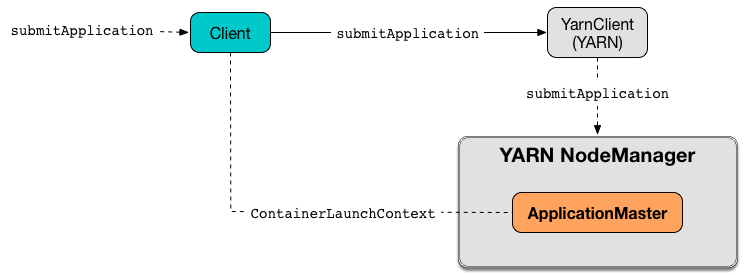
Figure 1. Launching ApplicationMaster
|
Note
|
ContainerLaunchContext represents all of the information needed by the YARN NodeManager to launch a container. |
client Internal Reference to YarnRMClient
client is the internal reference to YarnRMClient that ApplicationMaster is given when created.
client is primarily used to register the ApplicationMaster and request containers for executors from YARN and later unregister ApplicationMaster from YARN ResourceManager.
Besides, it helps obtaining an application attempt id and the allowed number of attempts to register ApplicationMaster. It also gets filter parameters to secure ApplicationMaster’s UI.
allocator Internal Reference to YarnAllocator
allocator is the internal reference to YarnAllocator that ApplicationMaster uses to request new or release outstanding containers for executors.
It is created when ApplicationMaster is registered (using the internal YarnRMClient reference).
main
ApplicationMaster is started as a standalone command-line application inside a YARN container on a node.
|
Note
|
The command-line application is executed as a result of sending a ContainerLaunchContext request to launch ApplicationMaster to YARN ResourceManager (after creating the request for ApplicationMaster)
|
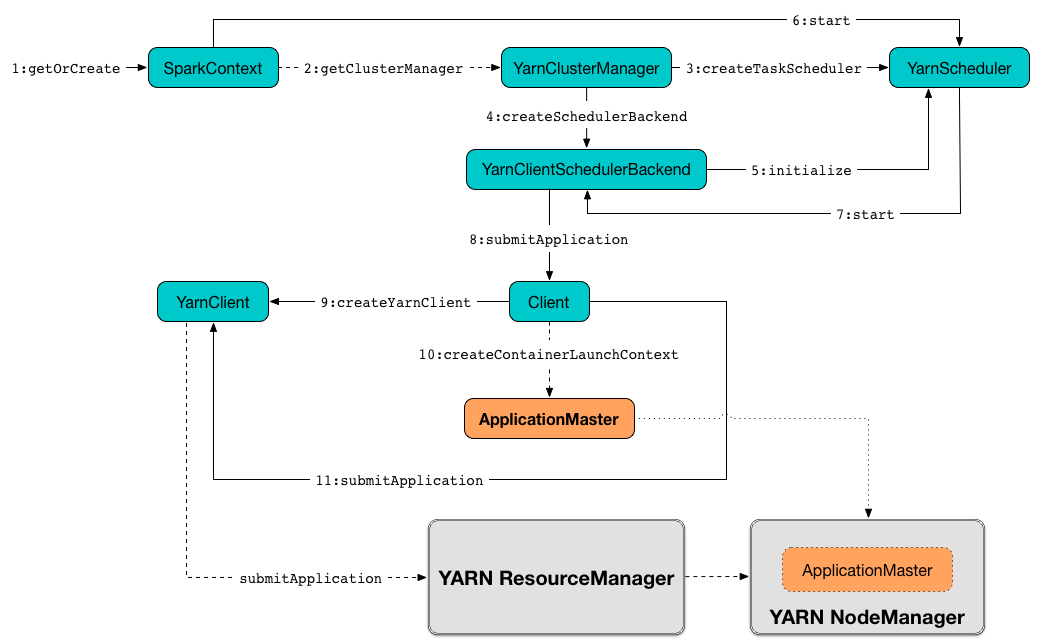
Figure 2. Submitting ApplicationMaster to YARN NodeManager
When executed, main first parses command-line parameters and then uses SparkHadoopUtil.runAsSparkUser to run the main code with a Hadoop UserGroupInformation as a thread local variable (distributed to child threads) for authenticating HDFS and YARN calls.
|
Tip
|
Enable Add the following line to Refer to Logging. |
You should see the following message in the logs:
DEBUG running as user: [user]SparkHadoopUtil.runAsSparkUser function executes a block that creates a ApplicationMaster (passing the ApplicationMasterArguments instance and a brand new YarnRMClient) and then runs it.
Command-Line Parameters (ApplicationMasterArguments class)
ApplicationMaster uses ApplicationMasterArguments class to handle command-line parameters.
ApplicationMasterArguments is created right after main method has been executed for args command-line parameters.
It accepts the following command-line parameters:
-
--jar JAR_PATH— the path to the Spark application’s JAR file -
--class CLASS_NAME— the name of the Spark application’s main class -
--arg ARG— an argument to be passed to the Spark application’s main class. There can be multiple--argarguments that are passed in order. -
--properties-file FILE— the path to a custom Spark properties file. -
--primary-py-file FILE— the main Python file to run. -
--primary-r-file FILE— the main R file to run.
When an unsupported parameter is found the following message is printed out to standard error output and ApplicationMaster exits with the exit code 1.
Unknown/unsupported param [unknownParam]
Usage: org.apache.spark.deploy.yarn.ApplicationMaster [options]
Options:
--jar JAR_PATH Path to your application's JAR file
--class CLASS_NAME Name of your application's main class
--primary-py-file A main Python file
--primary-r-file A main R file
--arg ARG Argument to be passed to your application's main class.
Multiple invocations are possible, each will be passed in order.
--properties-file FILE Path to a custom Spark properties file.Registering ApplicationMaster with YARN ResourceManager and Requesting Resources (registerAM method)
When runDriver or runExecutorLauncher are executed, they use the private helper procedure registerAM to register the ApplicationMaster (with the YARN ResourceManager) and request resources (given hints about where to allocate containers to be as close to the data as possible).
registerAM(
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: String,
securityMgr: SecurityManager): UnitInternally, it first reads spark.yarn.historyServer.address setting and substitute Hadoop variables to create a complete address of the History Server, i.e. [address]/history/[appId]/[attemptId].
|
Caution
|
FIXME substitute Hadoop variables? |
Then, registerAM creates a RpcEndpointAddress for CoarseGrainedScheduler RPC Endpoint on the driver available on spark.driver.host and spark.driver.port.
It registers the ApplicationMaster with the YARN ResourceManager and request resources (given hints about where to allocate containers to be as close to the data as possible).
Ultimately, registerAM launches reporter thread.
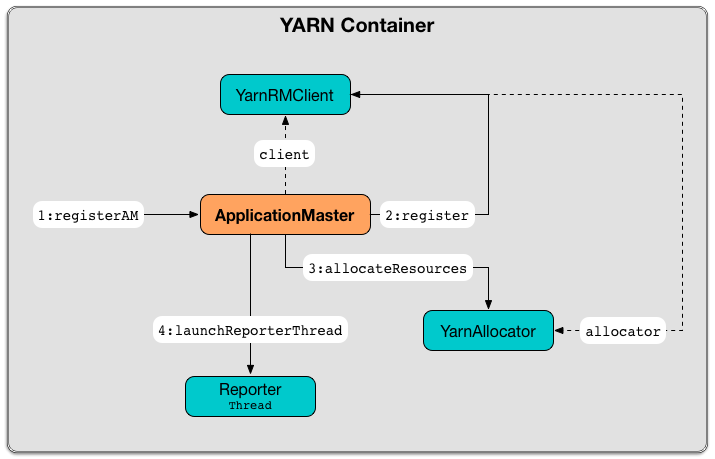
Figure 3. Registering ApplicationMaster with YARN ResourceManager
Running Driver in Cluster Mode (runDriver method)
runDriver(securityMgr: SecurityManager): UnitrunDriver is a private procedure to…???
It starts by registering Web UI security filters.
|
Caution
|
FIXME Why is this needed? addAmIpFilter
|
It then starts the user class (with the driver) in a separate thread. You should see the following INFO message in the logs:
INFO Starting the user application in a separate Thread|
Caution
|
FIXME Review startUserApplication.
|
You should see the following INFO message in the logs:
INFO Waiting for spark context initialization|
Caution
|
FIXME Review waitForSparkContextInitialized
|
|
Caution
|
FIXME Finish… |
Running Executor Launcher (runExecutorLauncher method)
runExecutorLauncher(securityMgr: SecurityManager): UnitrunExecutorLauncher reads spark.yarn.am.port (or assume 0) and starts the sparkYarnAM RPC Environment (in client mode).
|
Caution
|
FIXME What’s client mode? |
It then waits for the driver to be available.
|
Caution
|
FIXME Review waitForSparkDriver
|
It registers Web UI security filters.
|
Caution
|
FIXME Why is this needed? addAmIpFilter
|
Ultimately, runExecutorLauncher registers the ApplicationMaster and requests resources and waits until the reporterThread dies.
|
Caution
|
FIXME Describe registerAM
|
reporterThread
|
Caution
|
FIXME |
launchReporterThread
|
Caution
|
FIXME |
Setting Internal SparkContext Reference (sparkContextInitialized methods)
sparkContextInitialized(sc: SparkContext): UnitsparkContextInitialized passes the call on to the ApplicationMaster.sparkContextInitialized that sets the internal sparkContextRef reference (to be sc).
Clearing Internal SparkContext Reference (sparkContextStopped methods)
sparkContextStopped(sc: SparkContext): BooleansparkContextStopped passes the call on to the ApplicationMaster.sparkContextStopped that clears the internal sparkContextRef reference (i.e. sets it to null).
Creating ApplicationMaster Instance
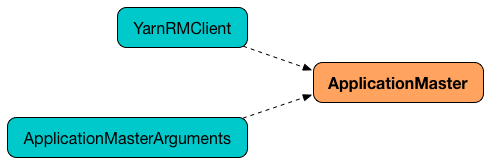
Figure 4. ApplicationMaster’s Dependencies
When creating an instance of ApplicationMaster it requires ApplicationMasterArguments and YarnRMClient.
It instantiates SparkConf and Hadoop’s YarnConfiguration (using SparkHadoopUtil.newConfiguration).
It assumes cluster deploy mode when --class was specified.
It computes the internal maxNumExecutorFailures using the optional spark.yarn.max.executor.failures if set. Otherwise, it is twice spark.executor.instances or spark.dynamicAllocation.maxExecutors (with dynamic allocation enabled) with the minimum of 3.
It reads yarn.am.liveness-monitor.expiry-interval-ms (default: 120000) from YARN to set the heartbeat interval. It is set to the minimum of the half of the YARN setting or spark.yarn.scheduler.heartbeat.interval-ms with the minimum of 0.
initialAllocationInterval is set to the minimum of the heartbeat interval or spark.yarn.scheduler.initial-allocation.interval.
It then loads the localized files (as set by the client).
|
Caution
|
FIXME Who’s the client? |
localResources attribute
When ApplicationMaster is instantiated, it computes internal localResources collection of YARN’s LocalResource by name based on the internal spark.yarn.cache.* configuration settings.
localResources: Map[String, LocalResource]You should see the following INFO message in the logs:
INFO ApplicationMaster: Preparing Local resourcesIt starts by reading the internal Spark configuration settings (that were earlier set when Client prepared local resources to distribute):
For each file name in spark.yarn.cache.filenames it maps spark.yarn.cache.types to an appropriate YARN’s LocalResourceType and creates a new YARN LocalResource.
|
Note
|
LocalResource represents a local resource required to run a container. |
If spark.yarn.cache.confArchive is set, it is added to localResources as ARCHIVE resource type and PRIVATE visibility.
|
Note
|
spark.yarn.cache.confArchive is set when Client prepares local resources.
|
|
Note
|
ARCHIVE is an archive file that is automatically unarchived by the NodeManager.
|
|
Note
|
PRIVATE visibility means to share a resource among all applications of the same user on the node.
|
Ultimately, it removes the cache-related settings from the Spark configuration and system properties.
You should see the following INFO message in the logs:
INFO ApplicationMaster: Prepared Local resources [resources]Running ApplicationMaster (run method)
When ApplicationMaster is started as a standalone command-line application (in a YARN container on a node in a YARN cluster), ultimately run is executed.
run(): IntThe result of calling run is the final result of the ApplicationMaster command-line application.
run sets cluster mode settings, registers the cleanup shutdown hook, schedules AMDelegationTokenRenewer and finally registers ApplicationMaster for the Spark application (either calling runDriver for cluster mode or runExecutorLauncher for client mode).
After the cluster mode settings are set, run prints the following INFO message out to the logs:
INFO ApplicationAttemptId: [appAttemptId]The appAttemptId is the current application attempt id (using the constructor’s YarnRMClient as client).
The cleanup shutdown hook is registered with shutdown priority lower than that of SparkContext (so it is executed after SparkContext).
SecurityManager is instantiated with the internal Spark configuration. If the credentials file config (as spark.yarn.credentials.file) is present, a AMDelegationTokenRenewer is started.
|
Caution
|
FIXME Describe AMDelegationTokenRenewer#scheduleLoginFromKeytab
|
It finally runs ApplicationMaster for the Spark application (either calling runDriver when in cluster mode or runExecutorLauncher otherwise).
It exits with 0 exit code.
In case of an exception, run prints the following ERROR message out to the logs:
ERROR Uncaught exception: [exception]And the application run attempt is finished with FAILED status and EXIT_UNCAUGHT_EXCEPTION (10) exit code.
Cluster Mode Settings
When in cluster mode, ApplicationMaster sets the following system properties (in run):
-
spark.ui.port as
0 -
spark.master as
yarn -
spark.submit.deployMode as
cluster -
spark.yarn.app.id as application id
|
Caution
|
FIXME Why are the system properties required? Who’s expecting them? |
isClusterMode Internal Flag
|
Caution
|
FIXME Since org.apache.spark.deploy.yarn.ExecutorLauncher is used for client deploy mode, the isClusterMode flag could be set there (not depending on --class which is correct yet not very obvious).
|
isClusterMode is an internal flag that is enabled (i.e. true) for cluster mode.
Specifically, it says whether the main class of the Spark application (through --class command-line argument) was specified or not. That is how the developers decided to inform ApplicationMaster about being run in cluster mode when Client creates YARN’s ContainerLaunchContext (for launching ApplicationMaster).
It is used to set additional system properties in run and runDriver (the flag is enabled) or runExecutorLauncher (when disabled).
Besides, it controls the default final status of a Spark application being FinalApplicationStatus.FAILED (when the flag is enabled) or FinalApplicationStatus.UNDEFINED.
The flag also controls whether to set system properties in addAmIpFilter (when the flag is enabled) or send a AddWebUIFilter instead.
Unregistering ApplicationMaster from YARN ResourceManager (unregister method)
unregister unregisters the ApplicationMaster for the Spark application from the YARN ResourceManager.
unregister(status: FinalApplicationStatus, diagnostics: String = null): Unit|
Note
|
It is called from the cleanup shutdown hook (that was registered in ApplicationMaster when it started running) and only when the application’s final result is successful or it was the last attempt to run the application.
|
It first checks that the ApplicationMaster has not already been unregistered (using the internal unregistered flag). If so, you should see the following INFO message in the logs:
INFO ApplicationMaster: Unregistering ApplicationMaster with [status]There can also be an optional diagnostic message in the logs:
(diag message: [msg])The internal unregistered flag is set to be enabled, i.e. true.
It then requests YarnRMClient to unregister.
Cleanup Shutdown Hook
When ApplicationMaster starts running, it registers a shutdown hook that unregisters the Spark application from the YARN ResourceManager and cleans up the staging directory.
Internally, it checks the internal finished flag, and if it is disabled, it marks the Spark application as failed with EXIT_EARLY.
If the internal unregistered flag is disabled, it unregisters the Spark application and cleans up the staging directory afterwards only when the final status of the ApplicationMaster’s registration is FinalApplicationStatus.SUCCEEDED or the number of application attempts is more than allowed.
The shutdown hook runs after the SparkContext is shut down, i.e. the shutdown priority is one less than SparkContext’s.
The shutdown hook is registered using Spark’s own ShutdownHookManager.addShutdownHook.
finish
|
Caution
|
FIXME |
ExecutorLauncher
ExecutorLauncher comes with no extra functionality when compared to ApplicationMaster. It serves as a helper class to run ApplicationMaster under another class name in client deploy mode.
With the two different class names (pointing at the same class ApplicationMaster) you should be more successful to distinguish between ExecutorLauncher (which is really a ApplicationMaster) in client deploy mode and the ApplicationMaster in cluster deploy mode using tools like ps or jps.
|
Note
|
Consider ExecutorLauncher a ApplicationMaster for client deploy mode.
|
Obtain Application Attempt Id (getAttemptId method)
getAttemptId(): ApplicationAttemptIdgetAttemptId returns YARN’s ApplicationAttemptId (of the Spark application to which the container was assigned).
Internally, it queries YARN by means of YarnRMClient.
addAmIpFilter helper method
addAmIpFilter(): UnitaddAmIpFilter is a helper method that …???
It starts by reading Hadoop’s environmental variable ApplicationConstants.APPLICATION_WEB_PROXY_BASE_ENV that it passes to YarnRMClient to compute the configuration for the AmIpFilter for web UI.
In cluster deploy mode (when ApplicationMaster runs with web UI), it sets spark.ui.filters system property as org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter. It also sets system properties from the key-value configuration of AmIpFilter (computed earlier) as spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.[key] being [value].
In client deploy mode (when ApplicationMaster runs on another JVM or even host than web UI), it simply sends a AddWebUIFilter to ApplicationMaster (namely to AMEndpoint RPC Endpoint).