
SparkContext — Entry Point to Spark (Core)
SparkContext (aka Spark context) is the entry point to Spark for a Spark application.
|
Note
|
You could also assume that a SparkContext instance is a Spark application. |
It sets up internal services and establishes a connection to a Spark execution environment (deployment mode).
Once a SparkContext instance is created you can use it to create RDDs, accumulators and broadcast variables, access Spark services and run jobs (until SparkContext is stopped).
A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application (don’t get confused with the other meaning of Master in Spark, though).
Figure 1. Spark context acts as the master of your Spark application
SparkContext offers the following functions:
-
Getting current configuration
-
Setting Configuration
-
Creating Distributed Entities
-
Accessing services, e.g. TaskScheduler, LiveListenerBus, BlockManager, SchedulerBackends, ShuffleManager.
-
Setting up custom Scheduler Backend, TaskScheduler and DAGScheduler
|
Tip
|
Read the scaladoc of org.apache.spark.SparkContext. |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Cancelling Job — cancelJob Method
cancelJob(jobId: Int)cancelJob requests DAGScheduler to cancel a Spark job jobId.
Persisted RDDs
|
Caution
|
FIXME |
persistRDD Method
persistRDD(rdd: RDD[_])persistRDD is a private[spark] method to register rdd in persistentRdds registry.
Programmable Dynamic Allocation
SparkContext offers the following methods as the developer API for dynamic allocation of executors:
Requesting New Executors — requestExecutors Method
requestExecutors(numAdditionalExecutors: Int): BooleanrequestExecutors requests numAdditionalExecutors executors from CoarseGrainedSchedulerBackend.
Requesting to Kill Executors — killExecutors Method
killExecutors(executorIds: Seq[String]): Boolean|
Caution
|
FIXME |
Requesting Total Executors — requestTotalExecutors Method
requestTotalExecutors(
numExecutors: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int]): BooleanrequestTotalExecutors is a private[spark] method that requests the exact number of executors from a coarse-grained scheduler backend.
|
Note
|
It works for coarse-grained scheduler backends only. |
When called for other scheduler backends you should see the following WARN message in the logs:
WARN Requesting executors is only supported in coarse-grained mode Getting Executor Ids — getExecutorIds Method
getExecutorIds is a private[spark] method that is a part of ExecutorAllocationClient contract. It simply passes the call on to the current coarse-grained scheduler backend, i.e. calls getExecutorIds.
|
Note
|
It works for coarse-grained scheduler backends only. |
When called for other scheduler backends you should see the following WARN message in the logs:
WARN Requesting executors is only supported in coarse-grained mode|
Caution
|
FIXME Why does SparkContext implement the method for coarse-grained scheduler backends? Why doesn’t SparkContext throw an exception when the method is called? Nobody seems to be using it (!) |
Creating SparkContext Instance
You can create a SparkContext instance with or without creating a SparkConf object first.
|
Note
|
You may want to read Inside Creating SparkContext to learn what happens behind the scenes when SparkContext is created.
|
Getting Existing or Creating New SparkContext — getOrCreate Methods
getOrCreate(): SparkContext
getOrCreate(conf: SparkConf): SparkContextgetOrCreate methods allow you to get the existing SparkContext or create a new one.
import org.apache.spark.SparkContext
val sc = SparkContext.getOrCreate()
// Using an explicit SparkConf object
import org.apache.spark.SparkConf
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkMe App")
val sc = SparkContext.getOrCreate(conf)The no-param getOrCreate method requires that the two mandatory Spark settings - master and application name - are specified using spark-submit.
Constructors
SparkContext()
SparkContext(conf: SparkConf)
SparkContext(master: String, appName: String, conf: SparkConf)
SparkContext(
master: String,
appName: String,
sparkHome: String = null,
jars: Seq[String] = Nil,
environment: Map[String, String] = Map())You can create a SparkContext instance using the four constructors.
import org.apache.spark.SparkConf
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkMe App")
import org.apache.spark.SparkContext
val sc = new SparkContext(conf)When a Spark context starts up you should see the following INFO in the logs (amongst the other messages that come from the Spark services):
INFO SparkContext: Running Spark version 2.0.0-SNAPSHOT|
Note
|
Only one SparkContext may be running in a single JVM (check out SPARK-2243 Support multiple SparkContexts in the same JVM). Sharing access to a SparkContext in the JVM is the solution to share data within Spark (without relying on other means of data sharing using external data stores). |
Getting Current SparkConf — getConf Method
getConf: SparkConfgetConf returns the current SparkConf.
|
Note
|
Changing the SparkConf object does not change the current configuration (as the method returns a copy).
|
Getting Deployment Environment — master Method
master: Stringmaster method returns the current value of spark.master which is the deployment environment in use.
Getting Application Name — appName Method
appName: StringappName returns the value of the mandatory spark.app.name setting.
|
Note
|
appName is used when SparkDeploySchedulerBackend starts, SparkUI creates a web UI, when postApplicationStart is executed, and for Mesos and checkpointing in Spark Streaming.
|
Getting Deploy Mode — deployMode Method
deployMode: StringdeployMode returns the current value of spark.submit.deployMode setting or client if not set.
Getting Scheduling Mode — getSchedulingMode Method
getSchedulingMode: SchedulingMode.SchedulingModegetSchedulingMode returns the current Scheduling Mode.
Getting Schedulable (Pool) by Name — getPoolForName Method
getPoolForName(pool: String): Option[Schedulable]getPoolForName returns a Schedulable by the pool name, if one exists.
|
Note
|
getPoolForName is part of the Developer’s API and may change in the future.
|
Internally, it requests the TaskScheduler for the root pool and looks up the Schedulable by the pool name.
It is exclusively used to show pool details in web UI (for a stage).
Getting All Pools — getAllPools Method
getAllPools: Seq[Schedulable]getAllPools collects the Pools in TaskScheduler.rootPool.
|
Note
|
TaskScheduler.rootPool is part of the TaskScheduler Contract.
|
|
Note
|
getAllPools is part of the Developer’s API.
|
|
Caution
|
FIXME Where is the method used? |
|
Note
|
getAllPools is used to calculate pool names for Stages tab in web UI with FAIR scheduling mode used.
|
Computing Default Level of Parallelism
Default level of parallelism is the number of partitions in RDDs when created without specifying them explicitly by a user.
It is used for the methods like SparkContext.parallelize, SparkContext.range and SparkContext.makeRDD (as well as Spark Streaming's DStream.countByValue and DStream.countByValueAndWindow and few other places). It is also used to instantiate HashPartitioner or for the minimum number of partitions in HadoopRDDs.
Internally, defaultParallelism relays requests for the default level of parallelism to TaskScheduler (it is a part of its contract).
Getting Spark Version — version Property
version: Stringversion returns the Spark version this SparkContext uses.
makeRDD Method
|
Caution
|
FIXME |
Submitting Jobs Asynchronously — submitJob Method
submitJob[T, U, R](
rdd: RDD[T],
processPartition: Iterator[T] => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit,
resultFunc: => R): SimpleFutureAction[R]submitJob submits a job in an asynchronous, non-blocking way to DAGScheduler.
It cleans the processPartition input function argument and returns an instance of SimpleFutureAction that holds the JobWaiter instance.
|
Caution
|
FIXME What are resultFunc?
|
It is used in:
Spark Configuration
|
Caution
|
FIXME |
SparkContext and RDDs
You use a Spark context to create RDDs (see Creating RDD).
When an RDD is created, it belongs to and is completely owned by the Spark context it originated from. RDDs can’t by design be shared between SparkContexts.
Figure 2. A Spark context creates a living space for RDDs.
Creating RDD — parallelize Method
SparkContext allows you to create many different RDDs from input sources like:
-
Scala’s collections, i.e.
sc.parallelize(0 to 100) -
local or remote filesystems, i.e.
sc.textFile("README.md") -
Any Hadoop
InputSourceusingsc.newAPIHadoopFile
Unpersisting RDDs (Marking RDDs as non-persistent) — unpersist Method
It removes an RDD from the master’s Block Manager (calls removeRdd(rddId: Int, blocking: Boolean)) and the internal persistentRdds mapping.
It finally posts SparkListenerUnpersistRDD message to listenerBus.
Setting Checkpoint Directory — setCheckpointDir Method
setCheckpointDir(directory: String)setCheckpointDir method is used to set up the checkpoint directory…FIXME
|
Caution
|
FIXME |
Registering Custom Accumulators — register Methods
register(acc: AccumulatorV2[_, _]): Unit
register(acc: AccumulatorV2[_, _], name: String): Unitregister registers the acc accumulator. You can optionally give an accumulator a name.
|
Tip
|
You can create built-in accumulators for longs, doubles, and collection types using specialized methods. |
Creating Built-In Accumulators
longAccumulator: LongAccumulator
longAccumulator(name: String): LongAccumulator
doubleAccumulator: DoubleAccumulator
doubleAccumulator(name: String): DoubleAccumulator
collectionAccumulator[T]: CollectionAccumulator[T]
collectionAccumulator[T](name: String): CollectionAccumulator[T]You can use longAccumulator, doubleAccumulator or collectionAccumulator to create and register accumulators for simple and collection values.
longAccumulator returns LongAccumulator with the zero value 0.
doubleAccumulator returns DoubleAccumulator with the zero value 0.0.
collectionAccumulator returns CollectionAccumulator with the zero value java.util.List[T].
scala> val acc = sc.longAccumulator
acc: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: None, value: 0)
scala> val counter = sc.longAccumulator("counter")
counter: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 1, name: Some(counter), value: 0)
scala> counter.value
res0: Long = 0
scala> sc.parallelize(0 to 9).foreach(n => counter.add(n))
scala> counter.value
res3: Long = 45The name input parameter allows you to give a name to an accumulator and have it displayed in Spark UI (under Stages tab for a given stage).
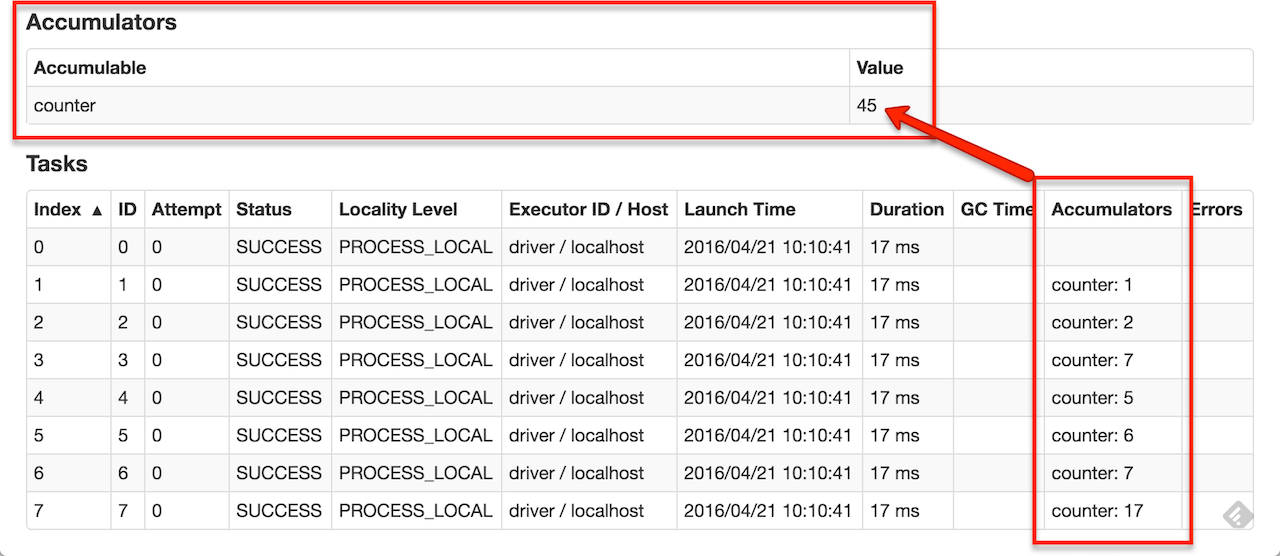
Figure 3. Accumulators in the Spark UI
|
Tip
|
You can register custom accumulators using register methods. |
Creating Broadcast Variables — broadcast Method
broadcast[T](value: T): Broadcast[T]broadcast method creates a broadcast variable that is a shared memory with value on all Spark executors.
scala> val hello = sc.broadcast("hello")
hello: org.apache.spark.broadcast.Broadcast[String] = Broadcast(0)Spark transfers the value to Spark executors once, and tasks can share it without incurring repetitive network transmissions when requested multiple times.
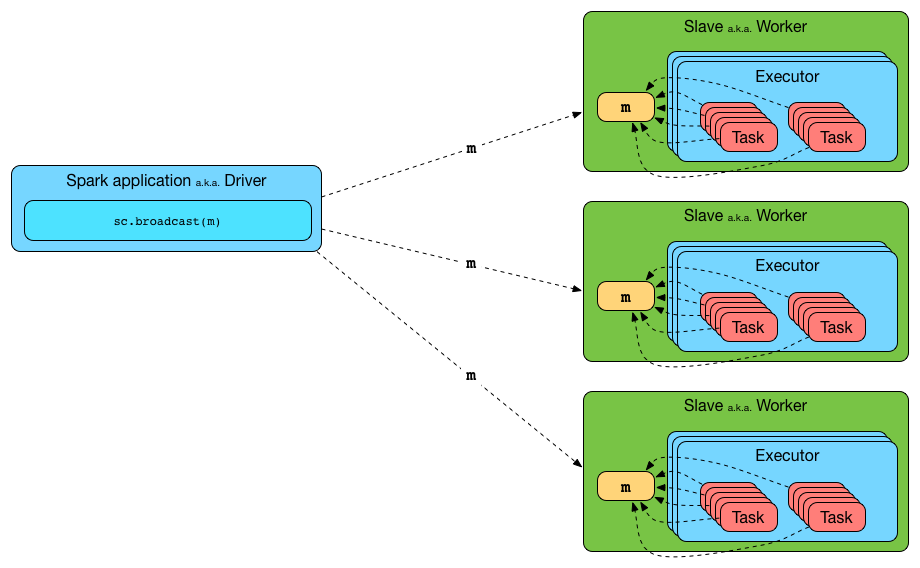
Figure 4. Broadcasting a value to executors
When a broadcast value is created the following INFO message appears in the logs:
INFO SparkContext: Created broadcast [id] from broadcast at <console>:25|
Note
|
Spark does not support broadcasting RDDs. |
Once created, the broadcast variable (and other blocks) are displayed per executor and the driver in web UI (under Executors tab).

Figure 5. Broadcast Variables In web UI’s Executors Tab
Distribute JARs to workers
The jar you specify with SparkContext.addJar will be copied to all the worker nodes.
The configuration setting spark.jars is a comma-separated list of jar paths to be included in all tasks executed from this SparkContext. A path can either be a local file, a file in HDFS (or other Hadoop-supported filesystems), an HTTP, HTTPS or FTP URI, or local:/path for a file on every worker node.
scala> sc.addJar("build.sbt")
15/11/11 21:54:54 INFO SparkContext: Added JAR build.sbt at http://192.168.1.4:49427/jars/build.sbt with timestamp 1447275294457|
Caution
|
FIXME Why is HttpFileServer used for addJar? |
SparkContext as the global configuration for services
SparkContext keeps track of:
-
shuffle ids using
nextShuffleIdinternal field for registering shuffle dependencies to Shuffle Service.
Running Job Synchronously — runJob Methods
RDD actions run jobs using one of runJob methods.
runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit
runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U]
runJob[T, U](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U]
runJob[T, U](rdd: RDD[T], func: (TaskContext, Iterator[T]) => U): Array[U]
runJob[T, U](rdd: RDD[T], func: Iterator[T] => U): Array[U]
runJob[T, U](
rdd: RDD[T],
processPartition: (TaskContext, Iterator[T]) => U,
resultHandler: (Int, U) => Unit)
runJob[T, U: ClassTag](
rdd: RDD[T],
processPartition: Iterator[T] => U,
resultHandler: (Int, U) => Unit)runJob executes a function on one or many partitions of a RDD (in a SparkContext space) to produce a collection of values per partition.
|
Note
|
runJob can only work when a SparkContext is not stopped.
|
Internally, runJob first makes sure that the SparkContext is not stopped. If it is, you should see the following IllegalStateException exception in the logs:
java.lang.IllegalStateException: SparkContext has been shutdown
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1893)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1914)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1934)
... 48 elidedrunJob then calculates the call site and cleans a func closure.
You should see the following INFO message in the logs:
INFO SparkContext: Starting job: [callSite]With spark.logLineage enabled (which is not by default), you should see the following INFO message with toDebugString (executed on rdd):
INFO SparkContext: RDD's recursive dependencies:
[toDebugString]runJob requests DAGScheduler to run a job.
|
Tip
|
runJob just prepares input parameters for DAGScheduler to run a job.
|
After DAGScheduler is done and the job has finished, runJob stops ConsoleProgressBar and performs RDD checkpointing of rdd.
|
Tip
|
For some actions, e.g. first() and lookup(), there is no need to compute all the partitions of the RDD in a job. And Spark knows it.
|
// RDD to work with
val lines = sc.parallelize(Seq("hello world", "nice to see you"))
import org.apache.spark.TaskContext
scala> sc.runJob(lines, (t: TaskContext, i: Iterator[String]) => 1) (1)
res0: Array[Int] = Array(1, 1) (2)-
Run a job using
runJobonlinesRDD with a function that returns 1 for every partition (oflinesRDD). -
What can you say about the number of partitions of the
linesRDD? Is your resultres0different than mine? Why?
|
Tip
|
Read TaskContext. |
Running a job is essentially executing a func function on all or a subset of partitions in an rdd RDD and returning the result as an array (with elements being the results per partition).
Figure 6. Executing action
postApplicationEnd Method
|
Caution
|
FIXME |
clearActiveContext Method
|
Caution
|
FIXME |
Stopping SparkContext — stop Method
stop(): Unitstop stops the SparkContext.
Internally, stop enables stopped internal flag. If already stopped, you should see the following INFO message in the logs:
INFO SparkContext: SparkContext already stopped.stop then does the following:
-
Removes
_shutdownHookReffromShutdownHookManager. -
Posts a
SparkListenerApplicationEnd(toLiveListenerBusEvent Bus). -
Requests
MetricSystemto report metrics (from all registered sinks). -
If
LiveListenerBuswas started, requestsLiveListenerBusto stop. -
Requests
EventLoggingListenerto stop. -
Requests
DAGSchedulerto stop. -
Requests
ConsoleProgressBarto stop. -
Clears the reference to
TaskScheduler, i.e._taskSchedulerisnull. -
Requests
SparkEnvto stop and clearsSparkEnv. -
Clears
SPARK_YARN_MODEflag.
Ultimately, you should see the following INFO message in the logs:
INFO SparkContext: Successfully stopped SparkContext Registering SparkListener — addSparkListener Method
addSparkListener(listener: SparkListenerInterface): UnitYou can register a custom SparkListenerInterface using addSparkListener method
|
Note
|
You can also register custom listeners using spark.extraListeners setting. |
Custom SchedulerBackend, TaskScheduler and DAGScheduler
By default, SparkContext uses (private[spark] class) org.apache.spark.scheduler.DAGScheduler, but you can develop your own custom DAGScheduler implementation, and use (private[spark]) SparkContext.dagScheduler_=(ds: DAGScheduler) method to assign yours.
It is also applicable to SchedulerBackend and TaskScheduler using schedulerBackend_=(sb: SchedulerBackend) and taskScheduler_=(ts: TaskScheduler) methods, respectively.
|
Caution
|
FIXME Make it an advanced exercise. |
Events
When a Spark context starts, it triggers SparkListenerEnvironmentUpdate and SparkListenerApplicationStart messages.
Refer to the section SparkContext’s initialization.
Setting Default Logging Level — setLogLevel Method
setLogLevel(logLevel: String)setLogLevel allows you to set the root logging level in a Spark application, e.g. Spark shell.
Internally, setLogLevel calls org.apache.log4j.Level.toLevel(logLevel) that it then uses to set using org.apache.log4j.LogManager.getRootLogger().setLevel(level).
|
Tip
|
You can directly set the logging level using org.apache.log4j.LogManager.getLogger(). |
Closure Cleaning — clean Method
clean(f: F, checkSerializable: Boolean = true): FEvery time an action is called, Spark cleans up the closure, i.e. the body of the action, before it is serialized and sent over the wire to executors.
SparkContext comes with clean(f: F, checkSerializable: Boolean = true) method that does this. It in turn calls ClosureCleaner.clean method.
Not only does ClosureCleaner.clean method clean the closure, but also does it transitively, i.e. referenced closures are cleaned transitively.
A closure is considered serializable as long as it does not explicitly reference unserializable objects. It does so by traversing the hierarchy of enclosing closures and null out any references that are not actually used by the starting closure.
|
Tip
|
Enable Add the following line to Refer to Logging. |
With DEBUG logging level you should see the following messages in the logs:
+++ Cleaning closure [func] ([func.getClass.getName]) +++
+ declared fields: [declaredFields.size]
[field]
...
+++ closure [func] ([func.getClass.getName]) is now cleaned +++Serialization is verified using a new instance of Serializer (as closure Serializer). Refer to Serialization.
|
Caution
|
FIXME an example, please. |
Hadoop Configuration
While a SparkContext is being created, so is a Hadoop configuration (as an instance of org.apache.hadoop.conf.Configuration that is available as _hadoopConfiguration).
|
Note
|
SparkHadoopUtil.get.newConfiguration is used. |
If a SparkConf is provided it is used to build the configuration as described. Otherwise, the default Configuration object is returned.
If AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY are both available, the following settings are set for the Hadoop configuration:
-
fs.s3.awsAccessKeyId,fs.s3n.awsAccessKeyId,fs.s3a.access.keyare set to the value ofAWS_ACCESS_KEY_ID -
fs.s3.awsSecretAccessKey,fs.s3n.awsSecretAccessKey, andfs.s3a.secret.keyare set to the value ofAWS_SECRET_ACCESS_KEY
Every spark.hadoop. setting becomes a setting of the configuration with the prefix spark.hadoop. removed for the key.
The value of spark.buffer.size (default: 65536) is used as the value of io.file.buffer.size.
listenerBus — LiveListenerBus Event Bus
listenerBus is a LiveListenerBus object that acts as a mechanism to announce events to other services on the driver.
|
Note
|
It is created and started when SparkContext starts and, since it is a single-JVM event bus, is exclusively used on the driver. |
|
Note
|
listenerBus is a private[spark] value in SparkContext.
|
Time when SparkContext was Created — startTime Property
startTime: LongstartTime is the time in milliseconds when SparkContext was created.
scala> sc.startTime
res0: Long = 1464425605653 Spark User — sparkUser Property
sparkUser: StringsparkUser is the user who started the SparkContext instance.
|
Note
|
It is computed when SparkContext is created using Utils.getCurrentUserName. |
Submitting Map Stage for Execution — submitMapStage Internal Method
submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C]): SimpleFutureAction[MapOutputStatistics]submitMapStage submits the map stage to DAGScheduler for execution and returns a SimpleFutureAction.
Internally, submitMapStage calculates the call site first and submits it with localProperties to DAGScheduler.
|
Note
|
Interestingly, submitMapStage is used exclusively when Spark SQL’s ShuffleExchange physical operator is executed.
|
Calculating Call Site — getCallSite Method
|
Caution
|
FIXME |
cancelJobGroup Method
cancelJobGroup(groupId: String)cancelJobGroup requests DAGScheduler to cancel a group of active Spark jobs.
cancelAllJobs Method
|
Caution
|
FIXME |
setJobGroup Method
setJobGroup(
groupId: String,
description: String,
interruptOnCancel: Boolean = false): Unit|
Caution
|
FIXME |
Settings
spark.driver.allowMultipleContexts
Quoting the scaladoc of org.apache.spark.SparkContext:
Only one SparkContext may be active per JVM. You must
stop()the active SparkContext before creating a new one.
You can however control the behaviour using spark.driver.allowMultipleContexts flag.
It is disabled, i.e. false, by default.
If enabled (i.e. true), Spark prints the following WARN message to the logs:
WARN Multiple running SparkContexts detected in the same JVM!If disabled (default), it will throw an SparkException exception:
Only one SparkContext may be running in this JVM (see SPARK-2243). To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at:
[ctx.creationSite.longForm]When creating an instance of SparkContext, Spark marks the current thread as having it being created (very early in the instantiation process).
|
Caution
|
It’s not guaranteed that Spark will work properly with two or more SparkContexts. Consider the feature a work in progress. |
Environment Variables
SPARK_EXECUTOR_MEMORY
SPARK_EXECUTOR_MEMORY sets the amount of memory to allocate to each executor. See Executor Memory.
SPARK_USER
SPARK_USER is the user who is running SparkContext. It is available later as sparkUser.