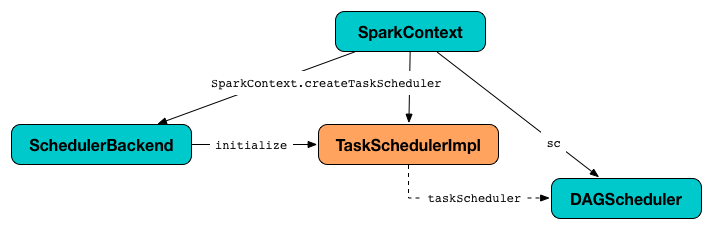
TaskSchedulerImpl — Default TaskScheduler
TaskSchedulerImpl is the default implementation of TaskScheduler Contract and extends it to track racks per host and port. It can schedule tasks for multiple types of cluster managers by means of Scheduler Backends.
Using spark.scheduler.mode setting you can select the scheduling policy.
It submits tasks using SchedulableBuilders.
When a Spark application starts (and an instance of SparkContext is created) TaskSchedulerImpl with a SchedulerBackend and DAGScheduler are created and soon started.
Figure 1. TaskSchedulerImpl and Other Services
|
Note
|
TaskSchedulerImpl is a private[spark] class with the source code in org.apache.spark.scheduler.TaskSchedulerImpl.
|
|
Tip
|
Enable Add the following line to Refer to Logging. |
starvationTimer
|
Caution
|
FIXME |
executorHeartbeatReceived Method
executorHeartbeatReceived(
execId: String,
accumUpdates: Array[(Long, Seq[AccumulatorV2[_, _]])],
blockManagerId: BlockManagerId): BooleanexecutorHeartbeatReceived is…
|
Caution
|
FIXME |
|
Note
|
executorHeartbeatReceived is a part of the TaskScheduler Contract.
|
Cancelling Tasks for Stage — cancelTasks Method
cancelTasks(stageId: Int, interruptThread: Boolean): UnitcancelTasks cancels all tasks submitted for execution in a stage stageId.
|
Note
|
It is currently called by DAGScheduler when it cancels a stage.
|
handleSuccessfulTask Method
handleSuccessfulTask(
taskSetManager: TaskSetManager,
tid: Long,
taskResult: DirectTaskResult[_]): UnithandleSuccessfulTask simply forwards the call to the input taskSetManager (passing tid and taskResult).
|
Note
|
handleSuccessfulTask is called when TaskSchedulerGetter has managed to deserialize the task result of a task that finished successfully.
|
handleTaskGettingResult Method
handleTaskGettingResult(taskSetManager: TaskSetManager, tid: Long): UnithandleTaskGettingResult simply forwards the call to the taskSetManager.
|
Note
|
handleTaskGettingResult is used to inform that TaskResultGetter enqueues a successful task with IndirectTaskResult task result (and so is about to fetch a remote block from a BlockManager).
|
schedulableBuilder Attribute
schedulableBuilder is a SchedulableBuilder for the TaskSchedulerImpl.
It is set up when a TaskSchedulerImpl is initialized and can be one of two available builders:
-
FIFOSchedulableBuilder when scheduling policy is FIFO (which is the default scheduling policy).
-
FairSchedulableBuilder for FAIR scheduling policy.
|
Note
|
Use spark.scheduler.mode setting to select the scheduling policy. |
Tracking Racks per Hosts and Ports — getRackForHost Method
getRackForHost(value: String): Option[String]getRackForHost is a method to know about the racks per hosts and ports. By default, it assumes that racks are unknown (i.e. the method returns None).
|
Note
|
It is overriden by the YARN-specific TaskScheduler YarnScheduler. |
getRackForHost is currently used in two places:
-
TaskSchedulerImpl.resourceOffers to track hosts per rack (using the internal
hostsByRackregistry) while processing resource offers. -
TaskSetManager.addPendingTask, TaskSetManager.dequeueTask, and TaskSetManager.dequeueSpeculativeTask
Internal Registries and Counters
| Name | Description |
|---|---|
|
The next task id counting from Used when |
Lookup table of TaskSet by stage and attempt ids. |
|
Lookup table of TaskSetManager by task id. |
|
Lookup table of executor by task id. |
|
Lookup table of the number of running tasks by executor. |
|
|
Collection of executors per host |
|
Collection of hosts per rack |
|
Lookup table of hosts per executor |
Creating TaskSchedulerImpl Instance
class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskSchedulerCreating a TaskSchedulerImpl object requires a SparkContext object with acceptable number of task failures and optional isLocal flag (disabled by default, i.e. false).
|
Note
|
There is another TaskSchedulerImpl constructor that requires a SparkContext object only and sets maxTaskFailures to spark.task.maxFailures or, if spark.task.maxFailures is not set, defaults to 4.
|
While being created, TaskSchedulerImpl initializes internal registries and counters to their default values.
TaskSchedulerImpl then sets schedulingMode to the value of spark.scheduler.mode setting (defaults to FIFO).
|
Note
|
schedulingMode is part of TaskScheduler Contract.
|
Failure to set schedulingMode results in a SparkException:
Unrecognized spark.scheduler.mode: [schedulingModeConf]Ultimately, TaskSchedulerImpl creates a TaskResultGetter.
Initializing TaskSchedulerImpl — initialize Method
initialize(backend: SchedulerBackend): Unitinitialize initializes a TaskSchedulerImpl object.
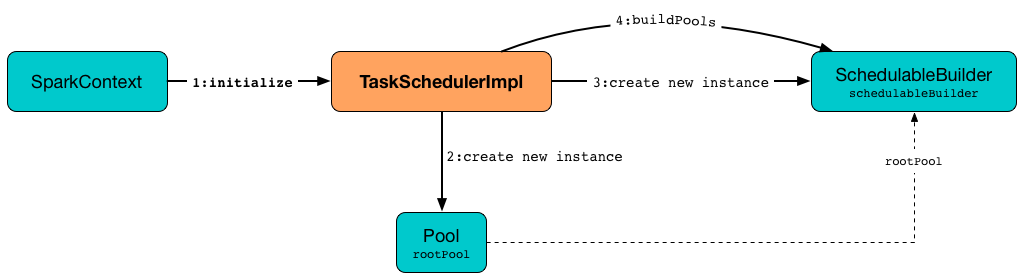
Figure 2. TaskSchedulerImpl initialization
|
Note
|
initialize is called while SparkContext is being created and creates SchedulerBackend and TaskScheduler.
|
initialize saves the reference to the current SchedulerBackend (as backend) and sets rootPool to be an empty-named Pool with already-initialized schedulingMode (while creating a TaskSchedulerImpl object), initMinShare and initWeight as 0.
|
Note
|
schedulingMode and rootPool are a part of TaskScheduler Contract.
|
It then creates the internal SchedulableBuilder object (as schedulableBuilder) based on schedulingMode:
-
FIFOSchedulableBuilder for
FIFOscheduling mode -
FairSchedulableBuilder for
FAIRscheduling mode
With the schedulableBuilder object created, initialize requests it to build pools.
|
Caution
|
FIXME Why are rootPool and schedulableBuilder created only now? What do they need that it is not available when TaskSchedulerImpl is created?
|
Starting TaskSchedulerImpl — start Method
As part of initialization of a SparkContext, TaskSchedulerImpl is started (using start from the TaskScheduler Contract).
start(): Unitstart starts the scheduler backend.
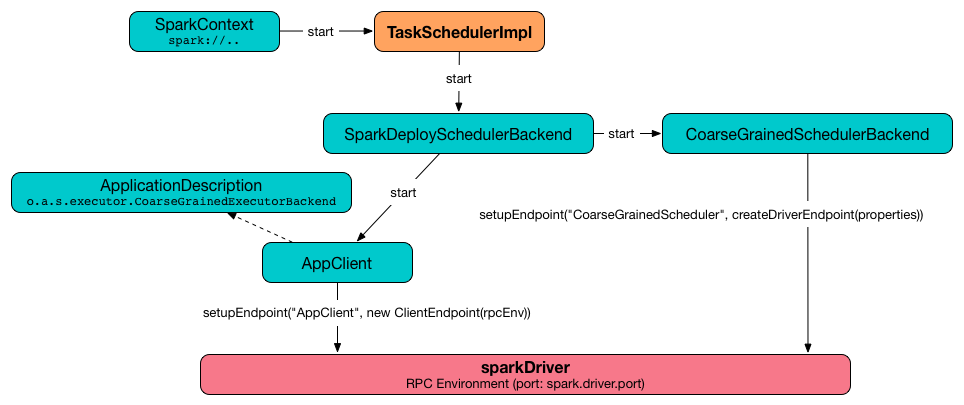
Figure 3. Starting
TaskSchedulerImpl in Spark Standalonestart also starts task-scheduler-speculation executor service.
task-scheduler-speculation Scheduled Executor Service — speculationScheduler Internal Attribute
speculationScheduler is a java.util.concurrent.ScheduledExecutorService with the name task-scheduler-speculation for speculative execution of tasks.
When TaskSchedulerImpl starts (in non-local run mode) with spark.speculation enabled, speculationScheduler is used to schedule checkSpeculatableTasks to execute periodically every spark.speculation.interval after the initial spark.speculation.interval passes.
speculationScheduler is shut down when TaskSchedulerImpl stops.
Checking for Speculatable Tasks — checkSpeculatableTasks Method
checkSpeculatableTasks(): UnitcheckSpeculatableTasks requests rootPool to check for speculatable tasks (if they ran for more than 100 ms) and, if there any, requests SchedulerBackend to revive offers.
|
Note
|
checkSpeculatableTasks is executed periodically as part of speculative execution of tasks.
|
Acceptable Number of Task Failures — maxTaskFailures Attribute
The acceptable number of task failures (maxTaskFailures) can be explicitly defined when creating TaskSchedulerImpl instance or based on spark.task.maxFailures setting that defaults to 4 failures.
|
Note
|
It is exclusively used when submitting tasks through TaskSetManager. |
Cleaning up After Removing Executor — removeExecutor Internal Method
removeExecutor(executorId: String, reason: ExecutorLossReason): UnitremoveExecutor removes the executorId executor from the following internal registries: executorIdToTaskCount, executorIdToHost, executorsByHost, and hostsByRack. If the affected hosts and racks are the last entries in executorsByHost and hostsByRack, appropriately, they are removed from the registries.
Unless reason is LossReasonPending, the executor is removed from executorIdToHost registry and TaskSetManagers get notified.
|
Note
|
The internal removeExecutor is called as part of statusUpdate and executorLost.
|
Local vs Non-Local Mode — isLocal Attribute
|
Caution
|
FIXME |
Post-Start Initialization — postStartHook Method
postStartHook is a custom implementation of postStartHook from the TaskScheduler Contract that waits until a scheduler backend is ready (using the internal blocking waitBackendReady).
|
Note
|
postStartHook is used when SparkContext is created (before it is fully created) and YarnClusterScheduler.postStartHook.
|
Waiting Until SchedulerBackend is Ready — waitBackendReady Method
The private waitBackendReady method waits until a SchedulerBackend is ready.
It keeps on checking the status every 100 milliseconds until the SchedulerBackend is ready or the SparkContext is stopped.
If the SparkContext happens to be stopped while doing the waiting, a IllegalStateException is thrown with the message:
Spark context stopped while waiting for backend Stopping TaskSchedulerImpl — stop Method
stop(): Unitstop() stops all the internal services, i.e. task-scheduler-speculation executor service, SchedulerBackend, TaskResultGetter, and starvationTimer timer.
Calculating Default Level of Parallelism — defaultParallelism Method
Default level of parallelism is a hint for sizing jobs. It is a part of the TaskScheduler contract and used by SparkContext to create RDDs with the right number of partitions when not specified explicitly.
TaskSchedulerImpl uses SchedulerBackend.defaultParallelism() to calculate the value, i.e. it just passes it along to a scheduler backend.
Submitting Tasks — submitTasks Method
|
Note
|
submitTasks is a part of TaskScheduler Contract.
|
submitTasks(taskSet: TaskSet): UnitsubmitTasks creates a TaskSetManager for the input TaskSet and adds it to the Schedulable root pool.
|
Note
|
The root pool can be a single flat linked queue (in FIFO scheduling mode) or a hierarchy of pools of Schedulables (in FAIR scheduling mode).
|
It makes sure that the requested resources, i.e. CPU and memory, are assigned to the Spark application for a non-local environment before requesting the current SchedulerBackend to revive offers.
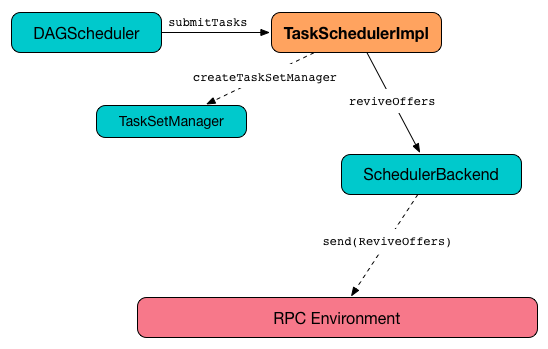
Figure 4. TaskSchedulerImpl.submitTasks
|
Note
|
If there are tasks to launch for missing partitions in a stage, DAGScheduler executes submitTasks (see submitMissingTasks for Stage and Job).
|
When submitTasks is called, you should see the following INFO message in the logs:
INFO TaskSchedulerImpl: Adding task set [taskSet.id] with [tasks.length] tasksIt creates a new TaskSetManager for the input taskSet and the acceptable number of task failures.
|
Note
|
The acceptable number of task failures is specified when a TaskSchedulerImpl is created. |
|
Note
|
A TaskSet knows the tasks to execute (as tasks) and stage id (as stageId) the tasks belong to. Read TaskSets.
|
The TaskSet is registered in the internal taskSetsByStageIdAndAttempt registry with the TaskSetManager.
If there is more than one active TaskSetManager for the stage, a IllegalStateException is thrown with the message:
more than one active taskSet for stage [stage]: [TaskSet ids]|
Note
|
TaskSetManager is considered active when it is not a zombie.
|
The TaskSetManager is added to the Schedulable pool (via SchedulableBuilder).
When the method is called the very first time (hasReceivedTask is false) in cluster mode only (i.e. isLocal of the TaskSchedulerImpl is false), starvationTimer is scheduled to execute after spark.starvation.timeout to ensure that the requested resources, i.e. CPUs and memory, were assigned by a cluster manager.
|
Note
|
After the first spark.starvation.timeout passes, the internal hasReceivedTask flag becomes true.
|
Every time the starvation timer thread is executed and hasLaunchedTask flag is false, the following WARN message is printed out to the logs:
WARN Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resourcesOtherwise, when the hasLaunchedTask flag is true the timer thread cancels itself.
Ultimately, submitTasks requests the SchedulerBackend to revive offers.
|
Tip
|
Use dag-scheduler-event-loop thread to step through the code in a debugger.
|
Processing Executor Resource Offers — resourceOffers Method
resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]]resourceOffers method is called by SchedulerBackend (for clustered environments) or LocalBackend (for local mode) with WorkerOffer resource offers that represent cores (CPUs) available on all the active executors with one WorkerOffer per active executor.
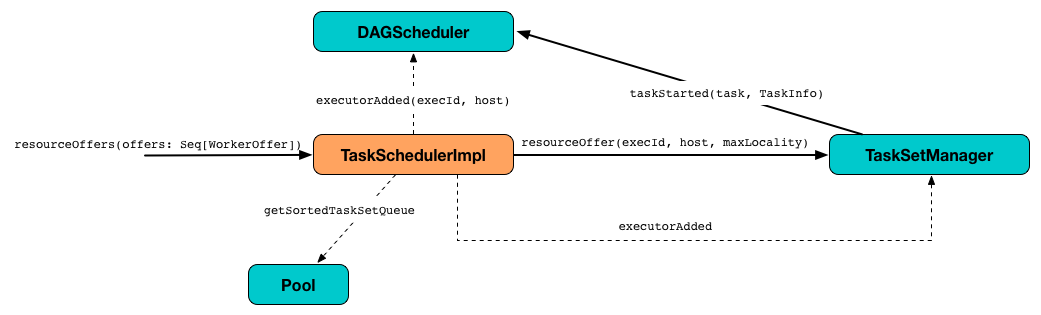
Figure 5. Processing Executor Resource Offers
|
Note
|
resourceOffers is a mechanism to propagate information about active executors to TaskSchedulerImpl with the hosts and racks (if supported by the cluster manager).
|
A WorkerOffer is a 3-tuple with executor id, host, and the number of free cores available.
WorkerOffer(executorId: String, host: String, cores: Int)For each WorkerOffer (that represents free cores on an executor) resourceOffers method records the host per executor id (using the internal executorIdToHost) and sets 0 as the number of tasks running on the executor if there are no tasks on the executor (using executorIdToTaskCount). It also records hosts (with executors in the internal executorsByHost registry).
|
Warning
|
FIXME BUG? Why is the executor id not added to executorsByHost?
|
For the offers with a host that has not been recorded yet (in the internal executorsByHost registry) the following occurs:
-
The host is recorded in the internal
executorsByHostregistry. -
executorAdded callback is called (with the executor id and the host from the offer).
-
newExecAvailflag is enabled (it is later used to informTaskSetManagersabout the new executor).
|
Caution
|
FIXME a picture with executorAdded call from TaskSchedulerImpl to DAGScheduler.
|
It shuffles the input offers that is supposed to help evenly distributing tasks across executors (that the input offers represent) and builds internal structures like tasks and availableCpus.
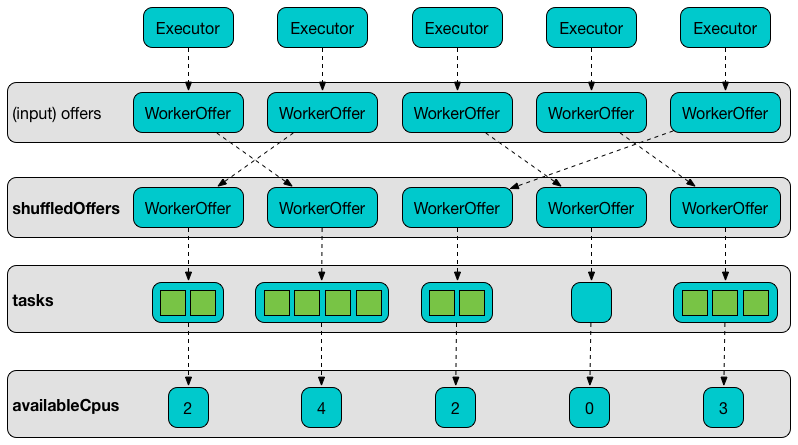
Figure 6. Internal Structures of resourceOffers with 5 WorkerOffers
The root pool is requested for TaskSetManagers sorted appropriately (according to the scheduling order).
|
Note
|
rootPool is a part of the TaskScheduler Contract and is exclusively managed by SchedulableBuilders (that add TaskSetManagers to the root pool.
|
For every TaskSetManager in the TaskSetManager sorted queue, the following DEBUG message is printed out to the logs:
DEBUG TaskSchedulerImpl: parentName: [taskSet.parent.name], name: [taskSet.name], runningTasks: [taskSet.runningTasks]|
Note
|
The internal rootPool is configured while TaskSchedulerImpl is being initialized.
|
While traversing over the sorted collection of TaskSetManagers, if a new host (with an executor) was registered, i.e. the newExecAvail flag is enabled, TaskSetManagers are informed about the new executor added.
|
Note
|
A TaskSetManager will be informed about one or more new executors once per host regardless of the number of executors registered on the host.
|
For each TaskSetManager (in sortedTaskSets) and for each preferred locality level (ascending), resourceOfferSingleTaskSet is called until launchedTask flag is false.
|
Caution
|
FIXME resourceOfferSingleTaskSet + the sentence above less code-centric.
|
Check whether the number of cores in an offer is greater than the number of cores needed for a task.
When resourceOffers managed to launch a task (i.e. tasks collection is not empty), the internal hasLaunchedTask flag becomes true (that effectively means what the name says "There were executors and I managed to launch a task").
resourceOffers returns the tasks collection.
|
Note
|
resourceOffers is called when CoarseGrainedSchedulerBackend makes resource offers.
|
resourceOfferSingleTaskSet Method
resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: Seq[ArrayBuffer[TaskDescription]]): BooleanresourceOfferSingleTaskSet is a private helper method that is executed when…
statusUpdate Method
statusUpdate(
tid: Long,
state: TaskState.TaskState,
serializedData: ByteBuffer): UnitstatusUpdate removes a lost executor when a tid task has failed. For all task states, statusUpdate removes the tid task from the internal registries, i.e. taskIdToTaskSetManager and taskIdToExecutorId, and decrements the number of running tasks in executorIdToTaskCount registry. For tid in FINISHED, FAILED, KILLED or LOST states, statusUpdate informs the TaskSetManager that the task can be removed from the running tasks. For tid in FINISHED state statusUpdate schedules an asynchrounous task to deserialize the task result (and notify TaskSchedulerImpl) while for FAILED, KILLED or LOST states it calls TaskResultGetter.enqueueFailedTask. Ultimately, given an executor that has been lost, statusUpdate informs informs DAGScheduler that the executor was lost and SchedulerBackend is requested to revive offers.
For tid task in LOST state and an executor still assigned for the task and tracked in executorIdToTaskCount registry, the executor is removed (with reason Task [tid] was lost, so marking the executor as lost as well.).
|
Caution
|
FIXME Why is SchedulerBackend.reviveOffers() called only for lost executors? |
statusUpdate looks up the TaskSetManager for tid (in taskIdToTaskSetManager registry).
When the TaskSetManager is found and the task is in a finished state, the task is removed from the internal registries, i.e. taskIdToTaskSetManager and taskIdToExecutorId, and the number of currently running tasks for the executor is decremented (in executorIdToTaskCount registry).
For a task in FINISHED state, the task is removed from the running tasks and an asynchrounous task is scheduled to deserialize the task result (and notify TaskSchedulerImpl).
For a task in FAILED, KILLED, or LOST state, the task is removed from the running tasks (as for the FINISHED state) and then TaskResultGetter.enqueueFailedTask is called.
If the TaskSetManager for tid could not be found (in taskIdToTaskSetManager registry), you should see the following ERROR message in the logs:
ERROR Ignoring update with state [state] for TID [tid] because its task set is gone (this is likely the result of receiving duplicate task finished status updates)Any exception is caught and reported as ERROR message in the logs:
ERROR Exception in statusUpdateUltimately, for tid task with an executor marked as lost, statusUpdate informs DAGScheduler that the executor was lost (with SlaveLost and the reason Task [tid] was lost, so marking the executor as lost as well.) and SchedulerBackend is requested to revive offers.
|
Caution
|
FIXME image with scheduler backends calling TaskSchedulerImpl.statusUpdate.
|
|
Note
|
statusUpdate is called when CoarseGrainedSchedulerBackend, LocalSchedulerBackend and MesosFineGrainedSchedulerBackend inform about task state changes.
|
Notifying TaskSetManager that Task Failed — handleFailedTask Method
handleFailedTask(
taskSetManager: TaskSetManager,
tid: Long,
taskState: TaskState,
reason: TaskFailedReason): UnithandleFailedTask notifies taskSetManager that tid task has failed and, only when taskSetManager is not in zombie state and tid is not in KILLED state, requests SchedulerBackend to revive offers.
|
Note
|
handleFailedTask is called when TaskResultGetter deserializes a TaskFailedReason for a failed task.
|
taskSetFinished Method
taskSetFinished(manager: TaskSetManager): UnittaskSetFinished looks all TaskSets up by the stage id (in taskSetsByStageIdAndAttempt registry) and removes the stage attempt from them, possibly with removing the entire stage record from taskSetsByStageIdAndAttempt registry completely (if there are no other attempts registered).
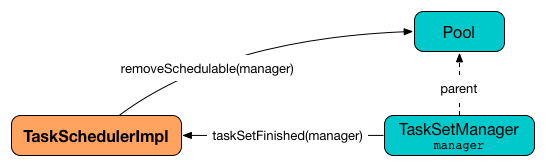
Figure 7. TaskSchedulerImpl.taskSetFinished is called when all tasks are finished
|
Note
|
A TaskSetManager manages a TaskSet for a stage.
|
taskSetFinished then removes manager from the parent’s schedulable pool.
You should see the following INFO message in the logs:
INFO Removed TaskSet [id], whose tasks have all completed, from pool [name]|
Note
|
taskSetFinished method is called when TaskSetManager has received the results of all the tasks in a TaskSet.
|
executorAdded Method
executorAdded(execId: String, host: String)executorAdded method simply passes the notification on to the DAGScheduler (using DAGScheduler.executorAdded)
|
Caution
|
FIXME Image with a call from TaskSchedulerImpl to DAGScheduler, please. |
Settings
| Spark Property | Default Value | Description |
|---|---|---|
|
The number of individual task failures before giving up on the entire TaskSet and the job afterwards. |
|
|
The number of CPUs to request per task. |
|
|
Threshold above which Spark warns a user that an initial TaskSet may be starved. |
|
|
A case-insensitive name of the scheduling mode — NOTE: Only |