transformation: RDD => RDD
transformation: RDD => Seq[RDD]Transformations
Transformations are lazy operations on a RDD that create one or many new RDDs, e.g. map, filter, reduceByKey, join, cogroup, randomSplit.
In other words, transformations are functions that take a RDD as the input and produce one or many RDDs as the output. They do not change the input RDD (since RDDs are immutable and hence cannot be modified), but always produce one or more new RDDs by applying the computations they represent.
By applying transformations you incrementally build a RDD lineage with all the parent RDDs of the final RDD(s).
Transformations are lazy, i.e. are not executed immediately. Only after calling an action are transformations executed.
After executing a transformation, the result RDD(s) will always be different from their parents and can be smaller (e.g. filter, count, distinct, sample), bigger (e.g. flatMap, union, cartesian) or the same size (e.g. map).
|
Caution
|
There are transformations that may trigger jobs, e.g. sortBy, zipWithIndex, etc.
|
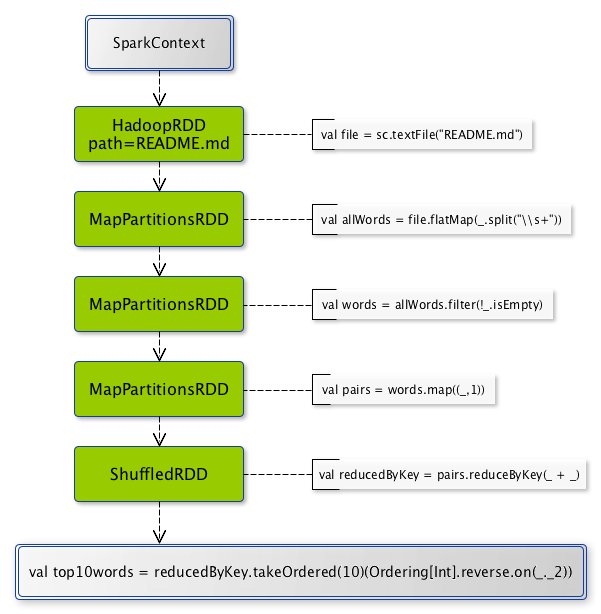
Figure 1. From SparkContext by transformations to the result
Certain transformations can be pipelined which is an optimization that Spark uses to improve performance of computations.
scala> val file = sc.textFile("README.md")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[54] at textFile at <console>:24
scala> val allWords = file.flatMap(_.split("\\W+"))
allWords: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[55] at flatMap at <console>:26
scala> val words = allWords.filter(!_.isEmpty)
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[56] at filter at <console>:28
scala> val pairs = words.map((_,1))
pairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[57] at map at <console>:30
scala> val reducedByKey = pairs.reduceByKey(_ + _)
reducedByKey: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[59] at reduceByKey at <console>:32
scala> val top10words = reducedByKey.takeOrdered(10)(Ordering[Int].reverse.on(_._2))
INFO SparkContext: Starting job: takeOrdered at <console>:34
...
INFO DAGScheduler: Job 18 finished: takeOrdered at <console>:34, took 0.074386 s
top10words: Array[(String, Int)] = Array((the,21), (to,14), (Spark,13), (for,11), (and,10), (##,8), (a,8), (run,7), (can,6), (is,6))There are two kinds of transformations:
Narrow Transformations
Narrow transformations are the result of map, filter and such that is from the data from a single partition only, i.e. it is self-sustained.
An output RDD has partitions with records that originate from a single partition in the parent RDD. Only a limited subset of partitions used to calculate the result.
Spark groups narrow transformations as a stage which is called pipelining.
Wide Transformations
Wide transformations are the result of groupByKey and reduceByKey. The data required to compute the records in a single partition may reside in many partitions of the parent RDD.
|
Note
|
Wide transformations are also called shuffle transformations as they may or may not depend on a shuffle. |
All of the tuples with the same key must end up in the same partition, processed by the same task. To satisfy these operations, Spark must execute RDD shuffle, which transfers data across cluster and results in a new stage with a new set of partitions.
mapPartitions
|
Caution
|
FIXME |
Using an external key-value store (like HBase, Redis, Cassandra) and performing lookups/updates inside of your mappers (creating a connection within a mapPartitions code block to avoid the connection setup/teardown overhead) might be a better solution.
If hbase is used as the external key value store, atomicity is guaranteed
zipWithIndex
zipWithIndex(): RDD[(T, Long)]zipWithIndex zips this RDD[T] with its element indices.
|
Caution
|
If the number of partitions of the source RDD is greater than 1, it will submit an additional job to calculate start indices. 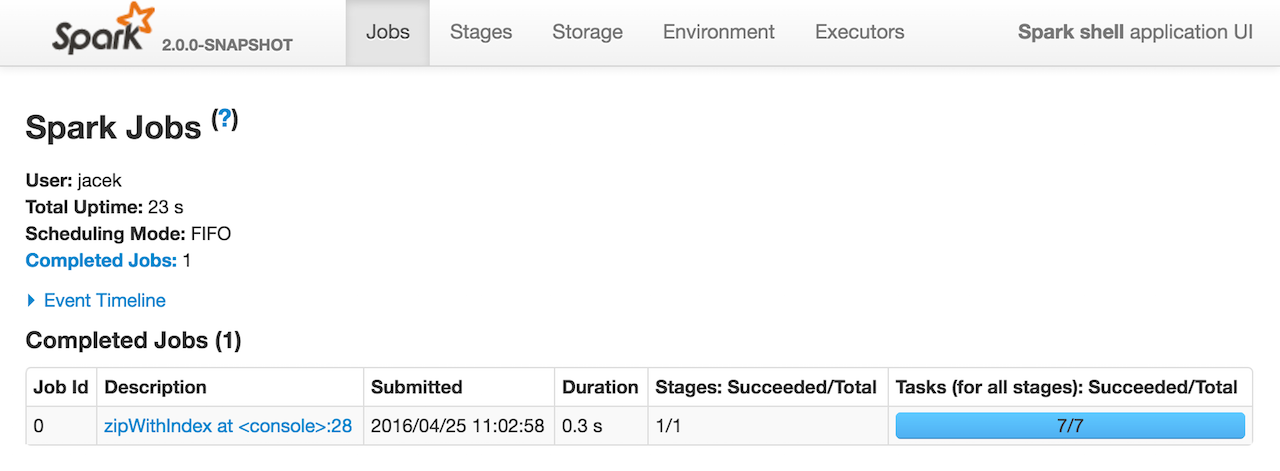
Figure 2. Spark job submitted by zipWithIndex transformation
|