scala> sc.parallelize(1 to 100).count
res0: Long = 100Partitions and Partitioning
Introduction
Depending on how you look at Spark (programmer, devop, admin), an RDD is about the content (developer’s and data scientist’s perspective) or how it gets spread out over a cluster (performance), i.e. how many partitions an RDD represents.
A partition (aka split) is…FIXME
|
Caution
|
|
Spark manages data using partitions that helps parallelize distributed data processing with minimal network traffic for sending data between executors.
By default, Spark tries to read data into an RDD from the nodes that are close to it. Since Spark usually accesses distributed partitioned data, to optimize transformation operations it creates partitions to hold the data chunks.
There is a one-to-one correspondence between how data is laid out in data storage like HDFS or Cassandra (it is partitioned for the same reasons).
Features:
-
size
-
number
-
partitioning scheme
-
node distribution
-
repartitioning
|
Tip
|
Read the following documentations to learn what experts say on the topic:
|
By default, a partition is created for each HDFS partition, which by default is 64MB (from Spark’s Programming Guide).
RDDs get partitioned automatically without programmer intervention. However, there are times when you’d like to adjust the size and number of partitions or the partitioning scheme according to the needs of your application.
You use def getPartitions: Array[Partition] method on a RDD to know the set of partitions in this RDD.
As noted in View Task Execution Against Partitions Using the UI:
When a stage executes, you can see the number of partitions for a given stage in the Spark UI.
Start spark-shell and see it yourself!
When you execute the Spark job, i.e. sc.parallelize(1 to 100).count, you should see the following in Spark shell application UI.
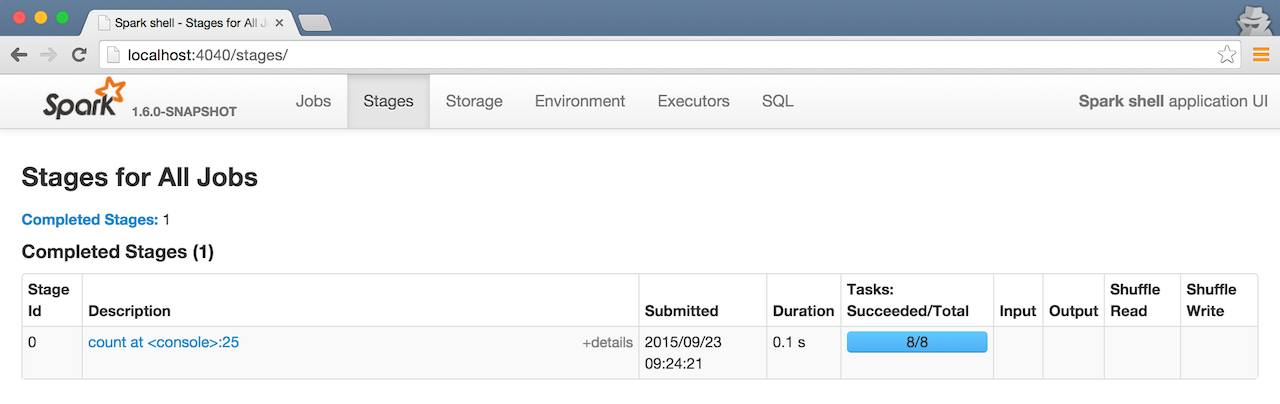
Figure 1. The number of partition as Total tasks in UI
The reason for 8 Tasks in Total is that I’m on a 8-core laptop and by default the number of partitions is the number of all available cores.
$ sysctl -n hw.ncpu
8You can request for the minimum number of partitions, using the second input parameter to many transformations.
scala> sc.parallelize(1 to 100, 2).count
res1: Long = 100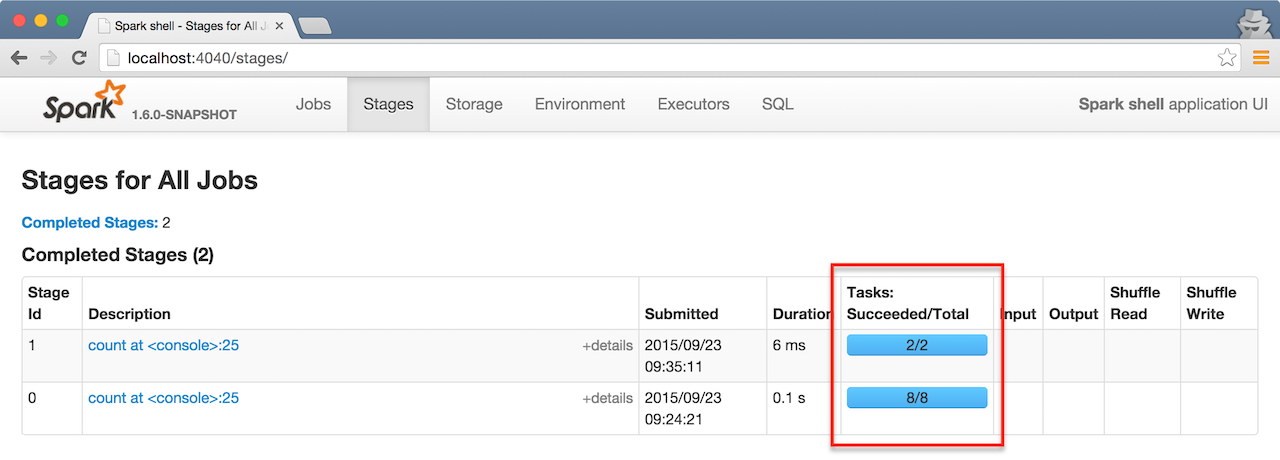
Figure 2. Total tasks in UI shows 2 partitions
You can always ask for the number of partitions using partitions method of a RDD:
scala> val ints = sc.parallelize(1 to 100, 4)
ints: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> ints.partitions.size
res2: Int = 4In general, smaller/more numerous partitions allow work to be distributed among more workers, but larger/fewer partitions allow work to be done in larger chunks, which may result in the work getting done more quickly as long as all workers are kept busy, due to reduced overhead.
Increasing partitions count will make each partition to have less data (or not at all!)
Spark can only run 1 concurrent task for every partition of an RDD, up to the number of cores in your cluster. So if you have a cluster with 50 cores, you want your RDDs to at least have 50 partitions (and probably 2-3x times that).
As far as choosing a "good" number of partitions, you generally want at least as many as the number of executors for parallelism. You can get this computed value by calling sc.defaultParallelism.
Also, the number of partitions determines how many files get generated by actions that save RDDs to files.
The maximum size of a partition is ultimately limited by the available memory of an executor.
In the first RDD transformation, e.g. reading from a file using sc.textFile(path, partition), the partition parameter will be applied to all further transformations and actions on this RDD.
Partitions get redistributed among nodes whenever shuffle occurs. Repartitioning may cause shuffle to occur in some situations, but it is not guaranteed to occur in all cases. And it usually happens during action stage.
When creating an RDD by reading a file using rdd = SparkContext().textFile("hdfs://…/file.txt") the number of partitions may be smaller. Ideally, you would get the same number of blocks as you see in HDFS, but if the lines in your file are too long (longer than the block size), there will be fewer partitions.
Preferred way to set up the number of partitions for an RDD is to directly pass it as the second input parameter in the call like rdd = sc.textFile("hdfs://…/file.txt", 400), where 400 is the number of partitions. In this case, the partitioning makes for 400 splits that would be done by the Hadoop’s TextInputFormat, not Spark and it would work much faster. It’s also that the code spawns 400 concurrent tasks to try to load file.txt directly into 400 partitions.
It will only work as described for uncompressed files.
When using textFile with compressed files (file.txt.gz not file.txt or similar), Spark disables splitting that makes for an RDD with only 1 partition (as reads against gzipped files cannot be parallelized). In this case, to change the number of partitions you should do repartitioning.
Some operations, e.g. map, flatMap, filter, don’t preserve partitioning.
map, flatMap, filter operations apply a function to every partition.
Repartitioning
-
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)does repartitioning with exactlynumPartitionspartitions. It uses coalesce andshuffleto redistribute data.
With the following computation you can see that repartition(5) causes 5 tasks to be started using NODE_LOCAL data locality.
scala> lines.repartition(5).count
...
15/10/07 08:10:00 INFO DAGScheduler: Submitting 5 missing tasks from ResultStage 7 (MapPartitionsRDD[19] at repartition at <console>:27)
15/10/07 08:10:00 INFO TaskSchedulerImpl: Adding task set 7.0 with 5 tasks
15/10/07 08:10:00 INFO TaskSetManager: Starting task 0.0 in stage 7.0 (TID 17, localhost, partition 0,NODE_LOCAL, 2089 bytes)
15/10/07 08:10:00 INFO TaskSetManager: Starting task 1.0 in stage 7.0 (TID 18, localhost, partition 1,NODE_LOCAL, 2089 bytes)
15/10/07 08:10:00 INFO TaskSetManager: Starting task 2.0 in stage 7.0 (TID 19, localhost, partition 2,NODE_LOCAL, 2089 bytes)
15/10/07 08:10:00 INFO TaskSetManager: Starting task 3.0 in stage 7.0 (TID 20, localhost, partition 3,NODE_LOCAL, 2089 bytes)
15/10/07 08:10:00 INFO TaskSetManager: Starting task 4.0 in stage 7.0 (TID 21, localhost, partition 4,NODE_LOCAL, 2089 bytes)
...You can see a change after executing repartition(1) causes 2 tasks to be started using PROCESS_LOCAL data locality.
scala> lines.repartition(1).count
...
15/10/07 08:14:09 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 8 (MapPartitionsRDD[20] at repartition at <console>:27)
15/10/07 08:14:09 INFO TaskSchedulerImpl: Adding task set 8.0 with 2 tasks
15/10/07 08:14:09 INFO TaskSetManager: Starting task 0.0 in stage 8.0 (TID 22, localhost, partition 0,PROCESS_LOCAL, 2058 bytes)
15/10/07 08:14:09 INFO TaskSetManager: Starting task 1.0 in stage 8.0 (TID 23, localhost, partition 1,PROCESS_LOCAL, 2058 bytes)
...Please note that Spark disables splitting for compressed files and creates RDDs with only 1 partition. In such cases, it’s helpful to use sc.textFile('demo.gz') and do repartitioning using rdd.repartition(100) as follows:
rdd = sc.textFile('demo.gz')
rdd = rdd.repartition(100)With the lines, you end up with rdd to be exactly 100 partitions of roughly equal in size.
-
rdd.repartition(N)does ashuffleto split data to matchN-
partitioning is done on round robin basis
-
|
Tip
|
If partitioning scheme doesn’t work for you, you can write your own custom partitioner. |
|
Tip
|
It’s useful to get familiar with Hadoop’s TextInputFormat. |
coalesce transformation
coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]The coalesce transformation is used to change the number of partitions. It can trigger RDD shuffling depending on the second shuffle boolean input parameter (defaults to false).
In the following sample, you parallelize a local 10-number sequence and coalesce it first without and then with shuffling (note the shuffle parameter being false and true, respectively). Use toDebugString to check out the RDD lineage graph.
scala> val rdd = sc.parallelize(0 to 10, 8)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.partitions.size
res0: Int = 8
scala> rdd.coalesce(numPartitions=8, shuffle=false) (1)
res1: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:27
scala> res1.toDebugString
res2: String =
(8) CoalescedRDD[1] at coalesce at <console>:27 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []
scala> rdd.coalesce(numPartitions=8, shuffle=true)
res3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at coalesce at <console>:27
scala> res3.toDebugString
res4: String =
(8) MapPartitionsRDD[5] at coalesce at <console>:27 []
| CoalescedRDD[4] at coalesce at <console>:27 []
| ShuffledRDD[3] at coalesce at <console>:27 []
+-(8) MapPartitionsRDD[2] at coalesce at <console>:27 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []-
shuffleisfalseby default and it’s explicitly used here for demo purposes. Note the number of partitions that remains the same as the number of partitions in the source RDDrdd.
Partitioner
|
Caution
|
FIXME |
A partitioner captures data distribution at the output. A scheduler can optimize future operations based on this.
val partitioner: Option[Partitioner] specifies how the RDD is partitioned.
HashPartitioner
|
Caution
|
FIXME |
HashPartitioner is the default partitioner for coalesce operation when shuffle is allowed, e.g. calling repartition.