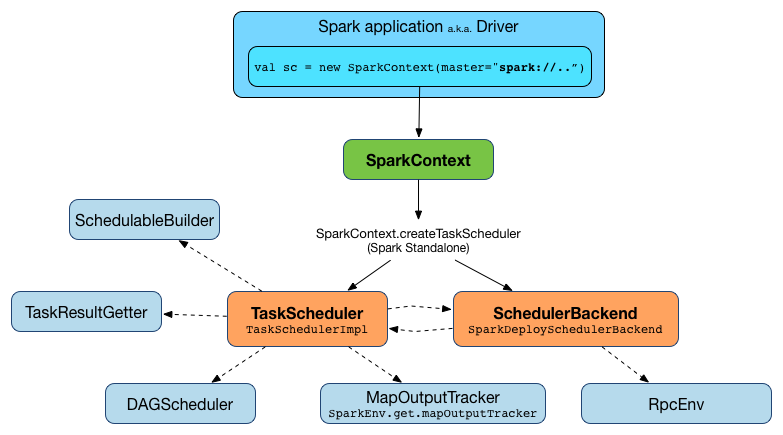
TaskScheduler
A TaskScheduler schedules tasks for a single Spark application according to scheduling mode.
Figure 1. TaskScheduler works for a single SparkContext
A TaskScheduler gets sets of tasks (as TaskSets) submitted to it from the DAGScheduler for each stage, and is responsible for sending the tasks to the cluster, running them, retrying if there are failures, and mitigating stragglers.
|
Note
|
TaskScheduler is a private[spark] Scala trait. You can find the sources in org.apache.spark.scheduler.TaskScheduler.
|
TaskScheduler Contract
|
Caution
|
FIXME Review the links since they really refer to TaskSchedulerImpl. Add the signatures.
|
Every TaskScheduler follows the following contract:
-
It can be started.
-
It can be stopped.
-
It can do post-start initialization if needed for additional post-start initialization.
-
It can cancel tasks for a stage.
-
It can set a custom DAGScheduler.
-
It can calculate the default level of parallelism.
-
It can handle executor’s heartbeats and executor lost events.
-
It has a
rootPoolPool (of Schedulables).
-
It can put tasks in order according to a scheduling policy (as
schedulingMode). It is used in SparkContext.getSchedulingMode.
|
Caution
|
FIXME Have an exercise to create a SchedulerBackend. |
TaskScheduler’s Lifecycle
A TaskScheduler is created while SparkContext is being created (by calling SparkContext.createTaskScheduler for a given master URL and deploy mode).
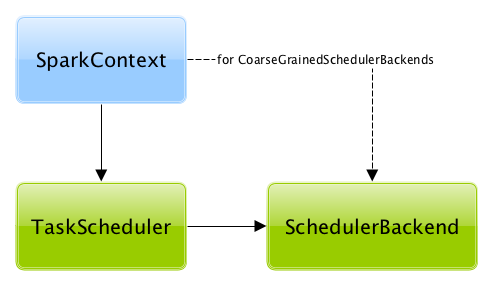
Figure 2. TaskScheduler uses SchedulerBackend to support different clusters
At this point in SparkContext’s lifecycle, the internal _taskScheduler points at the TaskScheduler (and it is "announced" by sending a blocking TaskSchedulerIsSet message to HeartbeatReceiver RPC endpoint).
The TaskScheduler is started right after the blocking TaskSchedulerIsSet message receives a response.
The application ID and the application’s attempt ID are set at this point (and SparkContext uses the application id to set up spark.app.id, SparkUI, and BlockManager).
|
Caution
|
FIXME The application id is described as "associated with the job." in TaskScheduler, but I think it is "associated with the application" and you can have many jobs per application. |
Right before SparkContext is fully initialized, TaskScheduler.postStartHook is called.
The internal _taskScheduler is cleared (i.e. set to null) while SparkContext is being stopped.
|
Warning
|
FIXME If it is SparkContext to start a TaskScheduler, shouldn’t SparkContext stop it too? Why is this the way it is now? |
Starting TaskScheduler — start Method
start(): Unitstart is currently called while SparkContext is being created.
Stopping TaskScheduler — stop Method
stop(): Unitstop is currently called while DAGScheduler is being stopped.
Post-Start Initialization — postStartHook Method
postStartHook() {}postStartHook does nothing by default, but allows custom implementations to do some post-start initialization.
|
Note
|
It is currently called right before SparkContext’s initialization finishes. |
Submitting TaskSets for Execution — submitTasks Method
submitTasks(taskSet: TaskSet): UnitsubmitTasks accepts a TaskSet for execution.
|
Note
|
It is currently called by DAGScheduler when there are tasks to be executed for a stage. |
Setting DAGScheduler — setDAGScheduler Method
setDAGScheduler(dagScheduler: DAGScheduler): UnitsetDAGScheduler sets the current DAGScheduler.
|
Note
|
It is currently called by DAGScheduler when it is created. |
Calculating Default Level of Parallelism — defaultParallelism Method
defaultParallelism(): IntdefaultParallelism calculates the default level of parallelism to use in a Spark application as the number of partitions in RDDs and also as a hint for sizing jobs.
|
Note
|
It is called by SparkContext for its defaultParallelism.
|
|
Tip
|
Read more in Calculating Default Level of Parallelism (defaultParallelism method) for the one and only implementation of the TaskScheduler contract — TaskSchedulerImpl.
|
Calculating Application ID — applicationId Method
applicationId(): StringapplicationId gives the current application’s id. It is in the format spark-application-[System.currentTimeMillis] by default.
|
Note
|
It is currently used in SparkContext while it is being initialized. |
Calculating Application Attempt ID — applicationAttemptId Method
applicationAttemptId(): Option[String]applicationAttemptId gives the current application’s attempt id.
|
Note
|
It is currently used in SparkContext while it is being initialized. |
Handling Executor’s Heartbeats — executorHeartbeatReceived Method
executorHeartbeatReceived(
execId: String,
accumUpdates: Array[(Long, Seq[AccumulatorV2[_, _]])],
blockManagerId: BlockManagerId): BooleanexecutorHeartbeatReceived handles heartbeats from an executor execId with the partial values of accumulators and BlockManagerId.
It is expected to be positive (i.e. return true) when the executor execId is managed by the TaskScheduler.
|
Note
|
It is currently used in HeartbeatReceiver RPC endpoint in SparkContext to handle heartbeats from executors. |
Handling Executor Lost Events — executorLost Method
executorLost(executorId: String, reason: ExecutorLossReason): UnitexecutorLost handles events about an executor executorId being lost for a given reason.
|
Note
|
It is currently used in HeartbeatReceiver RPC endpoint in SparkContext to process host expiration events and to remove executors in scheduler backends. |
Available Implementations
Spark comes with the following task schedulers:
-
YarnScheduler - the TaskScheduler for Spark on YARN in client deploy mode.
-
YarnClusterScheduler - the TaskScheduler for Spark on YARN in cluster deploy mode.