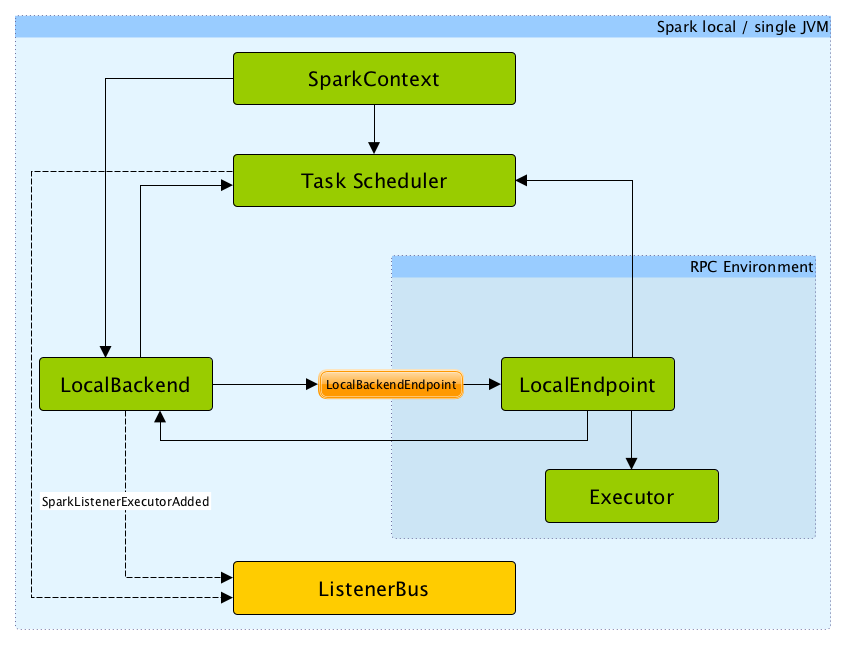
Spark local (pseudo-cluster)
You can run Spark in local mode. In this non-distributed single-JVM deployment mode, Spark spawns all the execution components - driver, executor, backend, and master - in the same single JVM. The default parallelism is the number of threads as specified in the master URL. This is the only mode where a driver is used for execution.
Figure 1. Architecture of Spark local
The local mode is very convenient for testing, debugging or demonstration purposes as it requires no earlier setup to launch Spark applications.
This mode of operation is also called Spark in-process or (less commonly) a local version of Spark.
SparkContext.isLocal returns true when Spark runs in local mode.
scala> sc.isLocal
res0: Boolean = trueSpark shell defaults to local mode with local[*] as the the master URL.
scala> sc.master
res0: String = local[*]Tasks are not re-executed on failure in local mode (unless local-with-retries master URL is used).
The task scheduler in local mode works with LocalBackend task scheduler backend.
Master URL
You can run Spark in local mode using local, local[n] or the most general local[*] for the master URL.
The URL says how many threads can be used in total:
-
localuses 1 thread only. -
local[n]usesnthreads. -
local[*]uses as many threads as the number of processors available to the Java virtual machine (it uses Runtime.getRuntime.availableProcessors() to know the number).
|
Caution
|
FIXME What happens when there’s less cores than n in the master URL? It is a question from twitter.
|
-
local[N, M](called local-with-retries) withNbeing*or the number of threads to use (as explained above) andMbeing the value of spark.task.maxFailures.
Task Submission a.k.a. reviveOffers
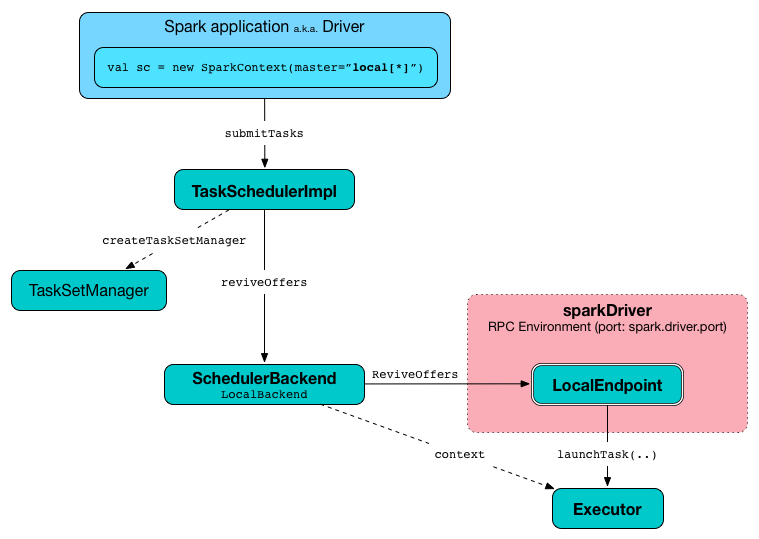
Figure 2. TaskSchedulerImpl.submitTasks in local mode
When ReviveOffers or StatusUpdate messages are received, LocalEndpoint places an offer to TaskSchedulerImpl (using TaskSchedulerImpl.resourceOffers).
If there is one or more tasks that match the offer, they are launched (using executor.launchTask method).
The number of tasks to be launched is controlled by the number of threads as specified in master URL. The executor uses threads to spawn the tasks.
LocalBackend
LocalBackend is a scheduler backend and a executor backend for Spark local mode.
It acts as a "cluster manager" for local mode to offer resources on the single worker it manages, i.e. it calls TaskSchedulerImpl.resourceOffers(offers) with offers being a single-element collection with WorkerOffer("driver", "localhost", freeCores).
|
Caution
|
FIXME Review freeCores. It appears you could have many jobs running simultaneously.
|
When an executor sends task status updates (using ExecutorBackend.statusUpdate), they are passed along as StatusUpdate to LocalEndpoint.
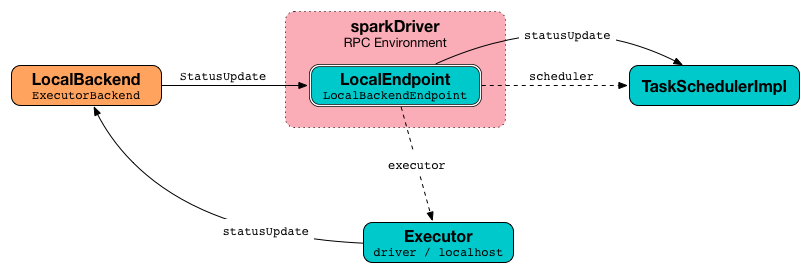
Figure 3. Task status updates flow in local mode
When LocalBackend starts up, it registers a new RPC Endpoint called LocalBackendEndpoint that is backed by LocalEndpoint. This is announced on LiveListenerBus as driver (using SparkListenerExecutorAdded message).
The application ids are in the format of local-[current time millis].
It communicates with LocalEndpoint using RPC messages.
The default parallelism is controlled using spark.default.parallelism.
LocalEndpoint
LocalEndpoint is the communication channel between Task Scheduler and LocalBackend. It is a (thread-safe) RPC Endpoint that hosts an executor (with id driver and hostname localhost) for Spark local mode.
When a LocalEndpoint starts up (as part of Spark local’s initialization) it prints out the following INFO messages to the logs:
INFO Executor: Starting executor ID driver on host localhost
INFO Executor: Using REPL class URI: http://192.168.1.4:56131Creating LocalEndpoint Instance
|
Caution
|
FIXME |
RPC Messages
LocalEndpoint accepts the following RPC message types:
-
ReviveOffers(receive-only, non-blocking) - read Task Submission a.k.a. reviveOffers. -
StatusUpdate(receive-only, non-blocking) that passes the message to TaskScheduler (usingstatusUpdate) and if the task’s status is finished, it revives offers (seeReviveOffers). -
KillTask(receive-only, non-blocking) that kills the task that is currently running on the executor. -
StopExecutor(receive-reply, blocking) that stops the executor.
Settings
-
spark.default.parallelism(default: the number of threads as specified in master URL) - the default parallelism for LocalBackend.