
YarnAllocator — Container Allocator
YarnAllocator allocates resource containers from YARN ResourceManager to run Spark executors on and releases them when the Spark application no longer needs them.
It talks directly to YARN ResourceManager through the amClient reference (of YARN’s AMRMClient[ContainerRequest] type) that it gets when created (from YarnRMClient when it registers the ApplicationMaster for a Spark application).
|
Caution
|
FIXME Image for YarnAllocator uses amClient Reference to YARN ResourceManager |
YarnAllocator is a part of the internal state of ApplicationMaster (via the internal allocator reference).
Figure 1. ApplicationMaster uses YarnAllocator (via allocator attribute)
When YarnAllocator is created, it requires driverUrl, Hadoop’s Configuration, a Spark configuration, YARN’s ApplicationAttemptId, a SecurityManager, and a collection of Hadoop’s LocalResources by their name. The parameters are later used for launching Spark executors in allocated YARN containers.
|
Caution
|
FIXME An image with YarnAllocator and multiple ExecutorRunnables. |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Creating YarnAllocator Instance
When YarnRMClient registers ApplicationMaster for a Spark application (with YARN ResourceManager) it creates a new YarnAllocator instance.
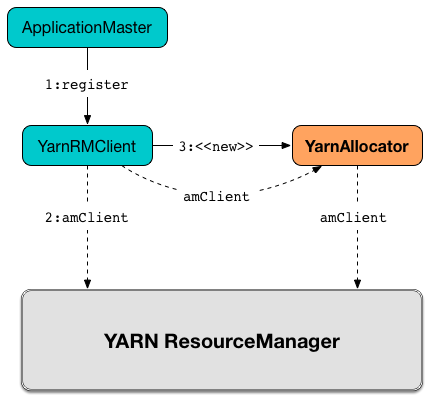
Figure 2. Creating YarnAllocator
All the input parameters for YarnAllocator (but appAttemptId and amClient) are passed directly from the input parameters of YarnRMClient.
YarnAllocator(
driverUrl: String,
driverRef: RpcEndpointRef,
conf: Configuration,
sparkConf: SparkConf,
amClient: AMRMClient[ContainerRequest],
appAttemptId: ApplicationAttemptId,
securityMgr: SecurityManager,
localResources: Map[String, LocalResource])The input amClient parameter is created in and owned by YarnRMClient.
When YarnAllocator is created, it sets the org.apache.hadoop.yarn.util.RackResolver logger to WARN (unless set to some log level already).
It creates the following empty registries:
It sets the following internal counters:
-
numExecutorsRunningto0 -
executorIdCounterto the last allocated executor id (it seems quite an extensive operation that uses a RPC system) -
numUnexpectedContainerReleaseto0L -
numLocalityAwareTasksto0 -
targetNumExecutorsto the initial number of executors
It creates an empty queue of failed executors.
It sets the internal executorFailuresValidityInterval to spark.yarn.executor.failuresValidityInterval.
It sets the internal executorMemory to spark.executor.memory.
It sets the internal memoryOverhead to spark.yarn.executor.memoryOverhead. If unavailable, it is set to the maximum of 10% of executorMemory and 384.
It sets the internal executorCores to spark.executor.cores.
It creates the internal resource to Hadoop YARN’s Resource with both executorMemory + memoryOverhead memory and executorCores CPU cores.
It creates the internal launcherPool called ContainerLauncher with maximum spark.yarn.containerLauncherMaxThreads threads.
It sets the internal launchContainers to spark.yarn.launchContainers.
It sets the internal labelExpression to spark.yarn.executor.nodeLabelExpression.
It sets the internal nodeLabelConstructor to…FIXME
|
Caution
|
FIXME nodeLabelConstructor? |
It sets the internal containerPlacementStrategy to…FIXME
|
Caution
|
FIXME LocalityPreferredContainerPlacementStrategy? |
Requesting Executors with Locality Preferences (requestTotalExecutorsWithPreferredLocalities method)
requestTotalExecutorsWithPreferredLocalities(
requestedTotal: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int]): BooleanrequestTotalExecutorsWithPreferredLocalities returns true if the current desired total number of executors is different than the input requestedTotal.
|
Note
|
requestTotalExecutorsWithPreferredLocalities should instead have been called shouldRequestTotalExecutorsWithPreferredLocalities since it answers the question whether to request total executors or not.
|
requestTotalExecutorsWithPreferredLocalities sets the internal numLocalityAwareTasks and hostToLocalTaskCounts attributes to the input localityAwareTasks and hostToLocalTaskCount arguments, respectively.
If the input requestedTotal is different than the internal targetNumExecutors attribute you should see the following INFO message in the logs:
INFO YarnAllocator: Driver requested a total number of [requestedTotal] executor(s).It sets the internal targetNumExecutors attribute to the input requestedTotal and returns true. Otherwise, it returns false.
|
Note
|
requestTotalExecutorsWithPreferredLocalities is executed in response to RequestExecutors message to ApplicationMaster.
|
numLocalityAwareTasks Internal Counter
numLocalityAwareTasks: Int = 0It tracks the number of locality-aware tasks to be used as container placement hint when YarnAllocator is requested for executors given locality preferences.
It is used as an input to containerPlacementStrategy.localityOfRequestedContainers when YarnAllocator updates YARN container allocation requests.
Adding or Removing Executor Container Requests (updateResourceRequests method)
updateResourceRequests(): UnitupdateResourceRequests requests new or cancels outstanding executor containers from the YARN ResourceManager.
|
Note
|
In YARN, you have to request containers for resources first (using AMRMClient.addContainerRequest) before calling AMRMClient.allocate. |
It gets the list of outstanding YARN’s ContainerRequests (using the constructor’s AMRMClient[ContainerRequest]) and aligns their number to current workload.
updateResourceRequests consists of two main branches:
-
missing executors, i.e. when the number of executors allocated already or pending does not match the needs and so there are missing executors.
-
executors to cancel, i.e. when the number of pending executor allocations is positive, but the number of all the executors is more than Spark needs.
Case 1. Missing Executors
You should see the following INFO message in the logs:
INFO YarnAllocator: Will request [count] executor containers, each with [vCores] cores and [memory] MB memory including [memoryOverhead] MB overheadIt then splits pending container allocation requests per locality preference of pending tasks (in the internal hostToLocalTaskCounts registry).
|
Caution
|
FIXME Review splitPendingAllocationsByLocality
|
It removes stale container allocation requests (using YARN’s AMRMClient.removeContainerRequest).
|
Caution
|
FIXME Stale? |
You should see the following INFO message in the logs:
INFO YarnAllocator: Canceled [cancelledContainers] container requests (locality no longer needed)It computes locality of requested containers (based on the internal numLocalityAwareTasks, hostToLocalTaskCounts and allocatedHostToContainersMap lookup table).
|
Caution
|
FIXME Review containerPlacementStrategy.localityOfRequestedContainers + the code that follows.
|
For any new container needed updateResourceRequests adds a container request (using YARN’s AMRMClient.addContainerRequest).
You should see the following INFO message in the logs:
INFO YarnAllocator: Submitted container request (host: [host], capability: [resource])Case 2. Cancelling Pending Executor Allocations
When there are executors to cancel (case 2.), you should see the following INFO message in the logs:
INFO Canceling requests for [numToCancel] executor container(s) to have a new desired total [targetNumExecutors] executors.It checks whether there are pending allocation requests and removes the excess (using YARN’s AMRMClient.removeContainerRequest). If there are no pending allocation requests, you should see the WARN message in the logs:
WARN Expected to find pending requests, but found none.killExecutor
|
Caution
|
FIXME |
Handling Allocated Containers for Executors (handleAllocatedContainers internal method)
When the YARN ResourceManager has allocated new containers for executors in allocateResources, the call is then passed on to handleAllocatedContainers procedure.
handleAllocatedContainers(allocatedContainers: Seq[Container]): UnithandleAllocatedContainers handles allocated YARN containers.
Internally, handleAllocatedContainers matches requests to host, rack, and any host (a container allocation).
If there are any allocated containers left (without having been matched), you should see the following DEBUG message in the logs:
DEBUG Releasing [size] unneeded containers that were allocated to usIt then releases the containers.
At the end of the method, you should see the following INFO message in the logs:
INFO Received [allocatedContainersSize] containers from YARN, launching executors on [containersToUseSize] of them.Launching Spark Executors in Allocated YARN Containers (runAllocatedContainers internal method)
runAllocatedContainers(containersToUse: ArrayBuffer[Container]): UnitFor each YARN’s Container in the input containersToUse collection, runAllocatedContainers attempts to run a ExecutorRunnable (on ContainerLauncher thread pool).
Internally, runAllocatedContainers increases the internal executorIdCounter counter and asserts that the amount of memory of (the resource allocated to) the container is greater than the requested memory for executors.
You should see the following INFO message in the logs:
INFO YarnAllocator: Launching container [containerId] for on host [executorHostname]Unless runAllocatedContainers runs in spark.yarn.launchContainers testing mode (when it merely updates internal state), you should see the following INFO message in the logs:
INFO YarnAllocator: Launching ExecutorRunnable. driverUrl: [driverUrl], executorHostname: [executorHostname]|
Note
|
driverUrl is of the form spark://CoarseGrainedScheduler@[host]:[port].
|
It executes ExecutorRunnable on ContainerLauncher thread pool and updates internal state.
Any non-fatal exception while running ExecutorRunnable is caught and you should see the following ERROR message in the logs:
ERROR Failed to launch executor [executorId] on container [containerId]It then immediately releases the failed container (using the internal AMRMClient).
updateInternalState
|
Caution
|
FIXME |
Releasing YARN Container (internalReleaseContainer internal procedure)
All unnecessary YARN containers (that were allocated but are either of no use or no longer needed) are released using the internal internalReleaseContainer procedure.
internalReleaseContainer(container: Container): UnitinternalReleaseContainer records container in the internal releasedContainers registry and releases it to the YARN ResourceManager (calling AMRMClient[ContainerRequest].releaseAssignedContainer using the internal amClient).
Deciding on Use of YARN Container (matchContainerToRequest internal method)
When handleAllocatedContainers handles allocated containers for executors, it uses matchContainerToRequest to match the containers to ContainerRequests (and hence to workload and location preferences).
matchContainerToRequest(
allocatedContainer: Container,
location: String,
containersToUse: ArrayBuffer[Container],
remaining: ArrayBuffer[Container]): UnitmatchContainerToRequest puts allocatedContainer in containersToUse or remaining collections per available outstanding ContainerRequests that match the priority of the input allocatedContainer, the input location, and the memory and vcore capabilities for Spark executors.
|
Note
|
The input location can be host, rack, or * (star), i.e. any host.
|
It gets the outstanding ContainerRequests (from the YARN ResourceManager).
If there are any outstanding ContainerRequests that meet the requirements, it simply takes the first one and puts it in the input containersToUse collection. It also removes the ContainerRequest so it is not submitted again (it uses the internal AMRMClient[ContainerRequest]).
Otherwise, it puts the input allocatedContainer in the input remaining collection.
ContainerLauncher Thread Pool
|
Caution
|
FIXME |
processCompletedContainers
processCompletedContainers(completedContainers: Seq[ContainerStatus]): UnitprocessCompletedContainers accepts a collection of YARN’s ContainerStatus'es.
|
Note
|
|
For each completed container in the collection, processCompletedContainers removes it from the internal releasedContainers registry.
It looks the host of the container up (in the internal allocatedContainerToHostMap lookup table). The host may or may not exist in the lookup table.
|
Caution
|
FIXME The host may or may not exist in the lookup table? |
The ExecutorExited exit reason is computed.
When the host of the completed container has been found, the internal numExecutorsRunning counter is decremented.
You should see the following INFO message in the logs:
INFO Completed container [containerId] [host] (state: [containerState], exit status: [containerExitStatus])For ContainerExitStatus.SUCCESS and ContainerExitStatus.PREEMPTED exit statuses of the container (which are not considered application failures), you should see one of the two possible INFO messages in the logs:
INFO Executor for container [id] exited because of a YARN event (e.g., pre-emption) and not because of an error in the running job.INFO Container [id] [host] was preempted.Other exit statuses of the container are considered application failures and reported as a WARN message in the logs:
WARN Container killed by YARN for exceeding memory limits. [diagnostics] Consider boosting spark.yarn.executor.memoryOverhead.or
WARN Container marked as failed: [id] [host]. Exit status: [containerExitStatus]. Diagnostics: [containerDiagnostics]The host is looked up in the internal allocatedHostToContainersMap lookup table. If found, the container is removed from the containers registered for the host or the host itself is removed from the lookup table when this container was the last on the host.
The container is removed from the internal allocatedContainerToHostMap lookup table.
The container is removed from the internal containerIdToExecutorId translation table. If an executor is found, it is removed from the internal executorIdToContainer translation table.
If the executor was recorded in the internal pendingLossReasonRequests lookup table, the exit reason (as calculated earlier as ExecutorExited) is sent back for every pending RPC message recorded.
If no executor was found, the executor and the exit reason are recorded in the internal releasedExecutorLossReasons lookup table.
In case the container was not in the internal releasedContainers registry, the internal numUnexpectedContainerRelease counter is increased and a RemoveExecutor RPC message is sent to the driver (as specified when YarnAllocator was created) to notify about the failure of the executor.
releasedExecutorLossReasons Internal Lookup Table
|
Caution
|
FIXME |
pendingLossReasonRequests Internal Lookup Table
|
Caution
|
FIXME |
executorIdToContainer Internal Translation Table
|
Caution
|
FIXME |
containerIdToExecutorId Internal Translation Table
|
Caution
|
FIXME |
allocatedHostToContainersMap Internal Lookup Table
|
Caution
|
FIXME |
numExecutorsRunning Internal Counter
|
Caution
|
FIXME |
allocatedContainerToHostMap Internal Lookup Table
|
Caution
|
FIXME |
Allocating YARN Containers for Executors and Cancelling Outstanding Containers (allocateResources method)
After ApplicationMaster is registered to the YARN ResourceManager Spark calls allocateResources.
allocateResources(): UnitallocateResources claims new resource containers from YARN ResourceManager and cancels any outstanding resource container requests.
|
Note
|
In YARN, you have to submit requests for resource containers to YARN ResourceManager first (using AMRMClient.addContainerRequest) before claiming them by calling AMRMClient.allocate. |
Internally, allocateResources starts by submitting requests for new containers and cancelling previous container requests.
allocateResources then claims the containers (using the internal reference to YARN’s AMRMClient) with progress indicator of 0.1f.
You can see the exact moment in the YARN console for the Spark application with the progress bar at 10%.

Figure 3. YARN Console after Allocating YARN Containers (Progress at 10%)
allocateResources gets the list of allocated containers from the YARN ResourceManager.
If the number of allocated containers is greater than 0, you should see the following DEBUG message in the logs (in stderr on YARN):
DEBUG YarnAllocator: Allocated containers: [allocatedContainersSize]. Current executor count: [numExecutorsRunning]. Cluster resources: [availableResources].allocateResources launches executors on the allocated YARN containers.
allocateResources gets the list of completed containers' statuses from YARN.
If the number of completed containers is greater than 0, you should see the following DEBUG message in the logs (in stderr on YARN):
DEBUG YarnAllocator: Completed [completedContainersSize] containersallocateResources processes completed containers.
You should see the following DEBUG message in the logs (in stderr on YARN):
DEBUG YarnAllocator: Finished processing [completedContainersSize] completed containers. Current running executor count: [numExecutorsRunning].Internal Registries
containerIdToExecutorId
|
Caution
|
FIXME |
executorIdToContainer
|
Caution
|
FIXME |
releasedExecutorLossReasons
|
Caution
|
FIXME |
pendingLossReasonRequests
|
Caution
|
FIXME |
failedExecutorsTimeStamps
|
Caution
|
FIXME |
releasedContainers Internal Registry
releasedContainers contains containers of no use anymore by their globally unique identifier ContainerId (for a Container in the cluster).
|
Note
|
Hadoop YARN’s Container represents an allocated resource in the cluster. The YARN ResourceManager is the sole authority to allocate any Container to applications. The allocated Container is always on a single node and has a unique ContainerId. It has a specific amount of Resource allocated.
|
Desired Total Number of Executors (targetNumExecutors Internal Attribute)
Initially, when YarnAllocator is created, targetNumExecutors corresponds to the initial number of executors.
targetNumExecutors is eventually reached after YarnAllocator updates YARN container allocation requests.
It may later be changed when YarnAllocator is requested for executors given locality preferences.